
Morgenstern, J. Research Roundup (January 2023), First10EM, January 30, 2023. Available at:
https://doi.org/10.51684/FIRS.129359
Back again with an eclectic collection of papers that might improve your practice, make you think, or just help you fall asleep at night. (Podcast available here.)
Shocking news (that everyone has already heard about)
DOSE VF: Cheskes S, Verbeek PR, Drennan IR, McLeod SL, Turner L, Pinto R, Feldman M, Davis M, Vaillancourt C, Morrison LJ, Dorian P, Scales DC. Defibrillation Strategies for Refractory Ventricular Fibrillation. N Engl J Med. 2022 Nov 6. doi: 10.1056/NEJMoa2207304. Epub ahead of print. PMID: 36342151
This is a huge trial that everyone will have heard about by now. The quick summary is that in out of hospital cardiac arrest with refractory ventricular fibrillation, dual sequential defibrillation (and to a lesser extent vector change defibrillation) beats standard ACLS, both in terms of survival to hospital discharge and neurologically intact survival. This will definitely change practice, and I think it should, but there are some important EBM caveats to be aware of. First, it is an open-label trial, which is understandable given the intervention, but lack of blinding can even influence very objective outcomes like mortality if there are subtle changes in the care provided to the different groups. Second, the trial was stopped early, not because of a pre-planned stopping point, but because of issues with COVID. Those are significant sources of bias, which add to the fact that a single trial will never get us close to 100% certainty.
Bottom line: This trial does not definitively prove that dual sequential defibrillation is beneficial, and future research absolutely should occur. However, given the relatively small downside and relatively large upside, I think almost all of us will incorporate this into practice until further research tells us otherwise.
In the short time since writing this, I encountered the rare patient still in refractory ventricular fibrillation on ED arrival, and for what it’s worth (not much) he did revert to sinus after the second attempt at dual sequential defibrillation.
You can read the full critical appraisal here.
Despite the rumors, not all endovascular therapy is miraculous
Vedantham S, Goldhaber SZ, Julian JA, et al; ATTRACT Trial Investigators. Pharmacomechanical Catheter-Directed Thrombolysis for Deep-Vein Thrombosis. N Engl J Med. 2017 Dec 7;377(23):2240-2252. doi: 10.1056/NEJMoa1615066. PMID: 29211671
I have recently heard it suggested that we should be using catheter directed thrombolysis for DVTs “based on the ATTRACT trial”. A hospital I work at is pushing this approach. Given the significant morbidity DVTs cause for patients, that sounded exciting. Then I actually read the paper. This is a big, open label, multi-center RCT that enrolled 692 patients with symptomatic proximal DVTs and randomized them to either pharmacomechanical-thrombolysis plus standard care or standard care alone. Standard care was rivaroxaban and compression stockings (a part many of us overlook). The primary outcome was the development of post-thrombotic syndrome, based on a somewhat subjective score, which can be problematic in an unblinded trial. That being said, the development of postthrombotic syndrome was identical (and frequent) in the two groups (47% vs 48%). The high risk of long term symptoms might be my biggest take home point. Remember to counsel your patients about this risk and the importance of compression stockings and follow-up. Obviously, bleeding and major bleeding were more in the thrombolytics group.
Bottom line: I am not sure how anyone can cite this specific paper as a push for a more aggressive approach to DVTs. I would suggest you ignore such pushes, as standard care gets you the same results with fewer side effects and a lower cost.
Interpretation of this paper depends entirely on whether members of your group actually clean ultrasound probes after use
Marks A, Patel D, Chottiner M, Kayarian F, Peksa GD, Gottlieb M. Covered or uncovered: A randomized control trial of Tegaderm versus no Tegaderm for ocular ultrasound. Am J Emerg Med. 2022 Nov;61:87-89. doi: 10.1016/j.ajem.2022.08.044. Epub 2022 Aug 28. PMID: 36057214
A quick but interesting study for anyone doing ocular ultrasound. It is a prospective cross-over RCT of adult patients presenting with visual complaints who were undergoing ocular ultrasound. (It was a convenience sample, with only specially trained ultrasound fellows performing the scans). Patients had an ultrasound of both eyes: one with a tegaderm and one without. Images were stored and then graded for quality by a blinded assessor. Image quality, the primary outcome, was statistically worse in the tegaderm group (mean difference 0.94 on a 5 point scale, p<0.001, which also sounds like it could be clinically important). There was no difference in patient reported discomfort (1.4/10 with tegaderm and 1.7 without). I made this switch a long time ago. Although it seems like the tegaderm would make things more comfortable for patients, I have actually found the opposite. Removing the tegaderm seems to cause more discomfort than just wiping away some gel, and the gel does not cause any discomfort at all if it gets in the eye. Anecdotally, I have also found that my image quality is better since abandoning the tegaderm. Of course, I frequently encounter probes covered in blood and other unnamed fluids from the prior user that I wouldn’t want anywhere near my own eye. Thus, interpretation of this data might depend on the maturity and responsibility of your physician group.
Bottom line: You can probably improve the image quality of ocular ultrasound by not using a tegaderm, without a change in discomfort. I would still discuss both options with the patient.
Just scratching the surface of medical technology
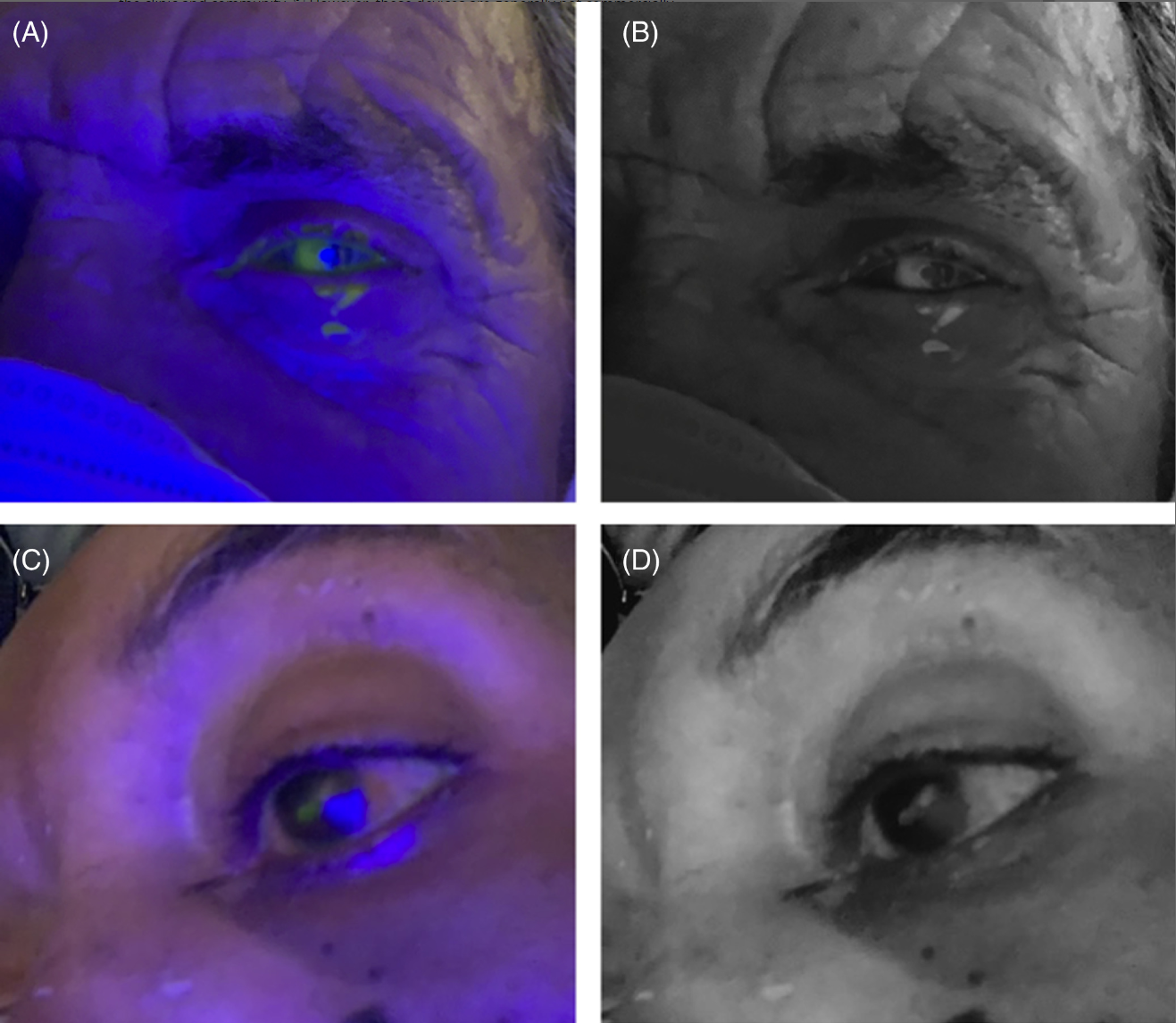
Hakimi AA, Carter S, Garg S. Detecting corneal injury with a selfie. Acad Emerg Med. 2022 Nov;29(11):1403-1404. doi: 10.1111/acem.14577. Epub 2022 Aug 17. PMID: 35921203
Not science, but an interesting publication nonetheless. These authors developed an app for the iphone that can be put into “cobalt blue selfie” mode, displaying cobalt blue, and allowing for fluorescein examinations with just an iphone. I am not sure why this would be needed in any emergency department, as every ophthalmoscope can also shine cobalt blue, but for anyone who does remote or overseas work, this 99 cent app might be worth it. Of course, this paper is more of an advertisement than a scientific publication, but I found it interesting. I would probably have been willing to drop the 99 cents to try it out, but I don’t have an iphone, so I have no idea if this app is any good.
The many problems with the HEART score
Green SM, Schriger DL. A Methodological Appraisal of the HEART Score and Its Variants. Ann Emerg Med. 2021 Aug;78(2):253-266. doi: 10.1016/j.annemergmed.2021.02.007. Epub 2021 Apr 29. PMID: 33933300
Warning: This summary is long and gets a little (or maybe more than a little) deep into the nerdy realm. Many readers might want to skip the details, but I think there is a lot of value in understanding the decision rules we are using (mostly inappropriately).
I have been on record many times saying we shouldn’t be using the HEART score. In order for a HEART score to provide value, you would have to be starting from a really bad spot, in which a large number of patients were being admitted to hospital unnecessarily. Considering that the combination of ECG and troponins has a miss rate of only 2-3 in 1,000, it is almost impossible that any decision tool will improve our practice. Superficially, this paper just goes over the many limitations of the evidence behind the HEART score. However, I chose to include it because I think it provides us with fantastic insight into decision rules in general, and their many many sources of weakness that we often overlook.
Did you know that the Annals of Emergency Medicine has a document outlining methodologic standards for decision rules? It is a checklist of things to consider when assessing a decision rule, which this paper reviews in the context of the HEART score:
- How were patients selected? An optimal decision rule is derived and tested in the population it is intended to apply, i.e. those for whom there is uncertainty about the diagnosis. If you include too many patients that are clinically obvious, it inflates the value of the decision rule on paper, but it won’t translate to practice. (The HEART studies included high risk patients with ischemic ECGs and positive troponins, but also low risk patients whose pain is almost certainly MSK or GI. We don’t need a rule to help with those patients, but the HEART score gets credit for classifying them correctly.)
- Does the outcome matter? Decision rules should look at outcomes that matter to patients. (The HEART studies used MACE, which is a composite that mixes some important outcomes with some clinically irrelevant outcomes.)
- Were all potentially important predictor variables included? To create a strong decision rule, you want the initial derivation set to look at all biologically plausible predictors. (The HEART score didn’t do this, but rather just selected 5 items in an intent to mirror the simplicity of the APGAR score.)
- Are the predictor variables objective or collected prospectively? Prospective derivation is important, because many variables are not reliably accounted for on chart review. (The HEART score was not originally derived prospectively, but it has since been tested prospectively.)
- Are the potential predictor variables reliable? If we are going to assign a seemingly objective risk score to patients, the components had better be objective, or we might be fooling ourselves. (The HEART score has clearly subjective variables, such as whether the history is suspicious. However, even the more objective seeming variables, such as troponin positivity, have imperfect inter-rater reliability. Overall, if you ask 2 different doctors to calculate the score, you will likely get 2 different answers. That’s not good.)
- How were the predictor variables coded? There are a number of ways that variables can be coded: binary (yes/no), graded ranks, or continuous (like the white count). It is important that the weighting of these variables is consistent with their actual positive likelihood ratios. (This is not the case for HEART, which is clear even without looking at the data. Significant ST depression is given the same weight in the score as having 3 risk factors. Similarly, being 46 years old gets you the same risk as being 64.)
- Was the derivation sample large enough? (The original HEART derivation had no sample size justification, and only included 122 patients.)
- Is the analytic technique appropriate? In general, this will mean using logistic regression and various forms of binary recursive partitioning. The point is to identify the variables that have the biggest impact on outcomes, while not including variables that are interdependent. (The HEART score was not derived this way, but rather based on clinical experience and a desire to create a rule as easy to use as the APGAR score). A major problem with decision rules is that when you start them with a set of variables derived from clinical judgment, you are really just codifying clinical judgment, but you end up only codifying some of the variables involved, and therefore are bound to end up worse than judgment.)
- Was the goal of the rule explicitly specified a priori? In order to be able to test and validate your rule, you need clear outcomes to test it against. For example, the PERC rule was designed to get below the test threshold of 1.8%, and therefore there is a clear criterion on which we can test to see if it succeeds. (There was no criterion for HEART.)
- Is the need for external validation before clinical application acknowledged? People love to rush to use new rules, and the authors really should be reminding us that the initial derivation and internal validation is only the first of many required steps. (We are beyond this point for the HEART score, as it has been externally validated, but the original paper was given “noncompliant” by these authors.)
- Can the rule itself be reliably assessed? Rules often seem objective, but if 5 different doctors would give you 5 different scores, that rule cannot help. (The interrater reliability of HEART has ranged from 29% to 46%).
- Are sensitivity and specificity both emphasized? Many rules emphasize their amazing sensitivity, while not mentioning their awful specificity that leave the rule completely unusable. (HEART originally did not report sensitivity or specificity, because it was not designed around a specific threshold. It provided ranges of risk, which these authors argue does not have clear value. I think that might be wrong, but it is hard to assess the value of a risk instrument that doesn’t specifically rule in or rule out.)
- Does the rule improve on baseline clinical practice? This is such an important question. Almost all decision rules are studied in a vacuum, and not compared to clinician judgment. When they are compared, they almost never improve on current practice, so why would we start using them? (There is no evidence that HEART improves on baseline clinical judgment, and it would be almost impossible to, given that our miss rate is less than 0.4% when we rely on nonischemic ECGs and negative troponins. There is an RCT showing improved practice with the HEART pathway, rather than the HEART score, but I think the comparison group is problematic due to American practices that diverge from the rest of the world.)
- Is the rules performance sufficiently precise? When considering rules, it is important to consider the uncertainty expressed in the 95% confidence intervals. A point estimate of 100% sensitivity might sound great, but often the 95% CI falls much lower than that. (As the HEART score was not designed to meet a specific outcome, it can’t really be validated, in that there is no specific criteria to determine if the rule passes or fails in a new cohort of patients. In meta-analyses, the lower bound of the 95% CI for the sensitivity of the HEART score seems to fall in the 93-94% range, consistent with missing 6-7% of MACE, which is higher than most would find acceptable.) These authors also emphasize that we should not be fooled by negative predictive values, which often exaggerate the values of rules, but instead focus on sensitivity and specificity. I think they are right about ignoring negative predictive values, but wrong about sensitivity and specificity. The numbers we really need to focus on are positive and negative likelihood ratios.
- Does the rule provide a 2-way course of action? The most useful rules tell us what to do both if they are positive and if they are negative. Although one way rules have a place, they are frequently miss-used, and when applied in the wrong population or interpreted as 2 way rules, they can cause a lot of harm. For example, the Canadian CT head rule is clearly a 1 way rule, but people frequently use it to justify ordering a CT, which is wrong, and results in massive over-testing. (The HEART score gets part grades here, but it is unclear what to do with patients with scores over 3, but with negative ECGs and troponins.)
Bottom line: 1) There are lots of reasons we shouldn’t be using the HEART score in clinical practice. 2) Although this was a very long summary, clinical decision rules are being introduced to practice at an increasing rate, and we need to have the tools to help decide whether they are helpful. (Most of the time they aren’t). Bookmark this page or this paper, so that you know what questions to ask when assessing the value of a new rule.
What happens when you ignore the troponin?
Khan A, Saleem MS, Willner KD, Sullivan L, Yu E, Mahmoud O, Alsaid A, Matsumura ME. Association of Chest Pain Protocol-Discordant Discharge With Outcomes Among Emergency Department Patients With Modest Elevations of High-Sensitivity Troponin. JAMA Netw Open. 2022 Aug 1;5(8):e2226809. doi: 10.1001/jamanetworkopen.2022.26809. Erratum in: JAMA Netw Open. 2022 Sep 1;5(9):e2235575. PMID: 35969395
This is a large retrospective observational study looking at the implementation of a high sensitivity troponin clinical decision pathway, and specifically at the subset of patients that were discharged from hospital against the recommendation of the clinical decision pathway. The algorithm is included in the image below, and looks like most algorithms widely in use. They included 10,342 patients, and 1166 (11.3%) were discharged from the ED despite the pathway suggesting admission. The overall rate of major adverse cardiac events among all patients discharged from the ED was 0.28%, which is exactly in line with all the other research on the topic, and demonstrates why these patients should not be referred for further testing, such as stress tests. Of the 1166 patients who were discharged against the clinical decision pathway, 16 (1.3%) had MACE within 30 days. This was statistically higher than those who followed the pathway (0.14% vs 1.3%, p<0.001), however it is still a very low number. This number is also almost certainly inflated, because they used the composite outcome of MACE which mixes clinically irrelevant outcomes with the outcomes we actually care about: MI and death. I guess my major question is whether these discharges were done on purpose, with good clinical judgment and shared decision making, or whether they were accidents based on a misunderstanding of the clinical decision pathway.
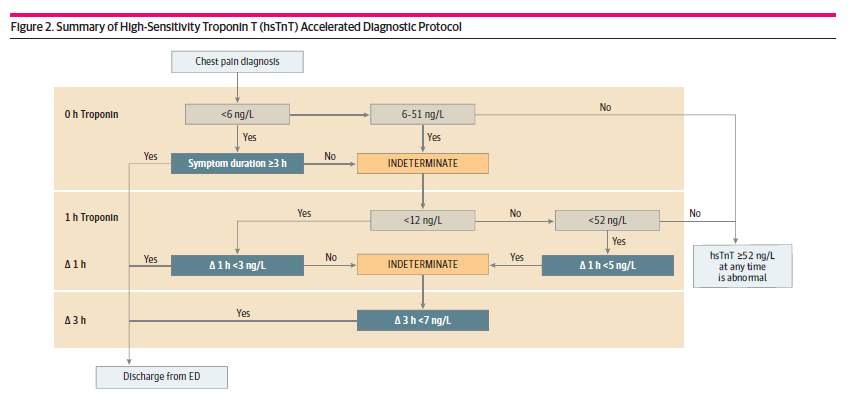
Bottom line: Patients who fail clinical decision pathways have a higher risk of major adverse cardiac events than those who pass the algorithms. However, in a carefully selected subset of those patients, the risk is probably still low enough to warrant consideration of discharge using a shared decision making model.
A mask might help with the stink of this one
Loeb M, Bartholomew A, Hashmi M, Tarhuni W, Hassany M, Youngster I, Somayaji R, Larios O, Kim J, Missaghi B, Vayalumkal JV, Mertz D, Chagla Z, Cividino M, Ali K, Mansour S, Castellucci LA, Frenette C, Parkes L, Downing M, Muller M, Glavin V, Newton J, Hookoom R, Leis JA, Kinross J, Smith S, Borhan S, Singh P, Pullenayegum E, Conly J. Medical Masks Versus N95 Respirators for Preventing COVID-19 Among Health Care Workers : A Randomized Trial. Ann Intern Med. 2022 Nov 29. doi: 10.7326/M22-1966. Epub ahead of print. PMID: 36442064
This study has received far more attention than it deserves, considering the quality of the research. You will hear headlines stating that N95s are no better than surgical masks in protecting against COVID-19, but this study doesn’t tell us that at all. You can read the full critical appraisal here, but the short summary is that they suggested wearing an N95 within 3 feet of patients with fever and cough in 1 group, and in the other group they suggested surgical masks, but allowed them to wear N95s whenever they wanted. Even in the N95 group, N95s were not worn when caring for patients without fever and cough. So ultimately they tested part time N95 use against part time N95 use (they don’t tell us the exact numbers, but the two groups could have worn N95s for exactly the same amount of time and still been protocol compliant.) Worse than that, they told nurses to doff 3 feet from a patient, so even the N95 group ignored the fact that COVID is spread through the airborne route, completely undermining the value of wearing an N95. So the trial was designed in such a way that both groups were guaranteed to look very similar. Even with those biases, there might be a small benefit to N95 use, and their subgroups show a larger benefit in Canada, where the study was originally supposed to be completed.
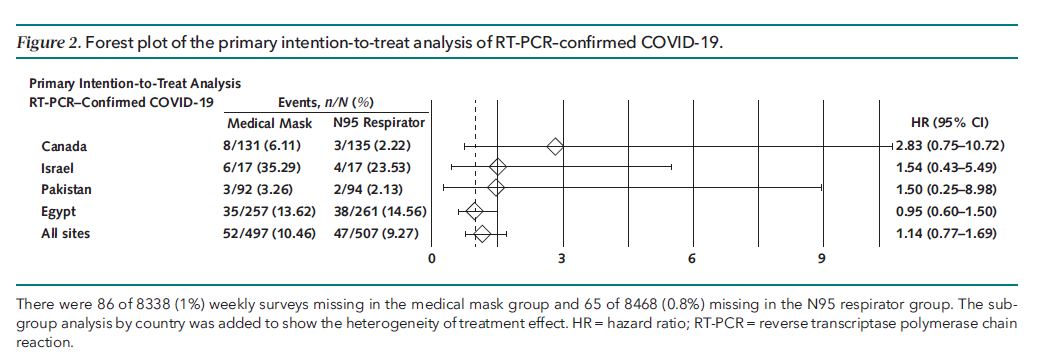
Bottom line: This study tells us almost nothing about the value of N95s. It definitely doesn’t prove they don’t work. It also doesn’t prove they do work, but when you combine it with all the science we have, I think it is pretty clear that an N95 will provide a small benefit in protection over surgical masks when caring for patients with airborne pathogens such as COVID-19 and influenza.
Some basic wound dogma
Kappel S, Kleinerman R, King TH, Sivamani R, Taylor S, Nguyen U, Eisen DB. Does wound eversion improve cosmetic outcome?: Results of a randomized, split-scar, comparative trial. J Am Acad Dermatol. 2015 Apr;72(4):668-73. doi: 10.1016/j.jaad.2014.11.032. Epub 2015 Jan 23. PMID: 25619206
This paper was covered in the laceration evidence series. It is a single center randomized trial looking at 50 adult patients undergoing dermatologic procedures. Wounds were divided in half. Half was closed using a suture designed to produce eversion, and the other half of the wound was closed the simple interrupted sutures with the aim of ‘planar’ closure. At 3 and 6 month follow-up, there was no difference in the appearance of the wound based on the “Patient Observer Self-Assessment Scale”, nor were there objective differences in measured height, width, or depth of the scars. As far as I know, this is the only trial to ever address this question. In their introduction section they state that, “data supporting improved outcomes with eversion are limited. No studies, to our knowledge, have directly addressed this facet of wound closure.” This is a single center study, with incomplete follow-up, incomplete blinding, inadequate allocation concealment, and incomplete follow-up.
Bottom line: It is not a high level of evidence, but it is literally all the evidence we have. I think the outcome fits with simple common-sense physiologic reasoning: there is no benefit of eversion over simple planar wound closure.
Does pediatrics get your heart rate up?
Kazmierczak M, Thompson AD, DePiero AD, Selbst SM. Outcomes of patients discharged from the pediatric emergency department with abnormal vital signs. Am J Emerg Med. 2022 Jul;57:76-80. doi: 10.1016/j.ajem.2022.04.021. Epub 2022 Apr 26. PMID: 35526404
Vital signs are, of course, vital, but they are also incredibly nonspecific. What percentage of patients with tachycardia actually have important pathology? I see a lot of practitioners who work very hard to ensure that children’s vital signs are perfect before discharging, providing fluids, and analgesia, and often significantly delaying the child’s discharge. However, if you really believe that every child needs normal vital signs before discharge, you do not have enough experience in pediatrics. Vital sign abnormalities are incredibly common in children, whether from pain, anxiety, fever, or a hundred other causes, and they almost never indicate underlying pathology, and do not, on their own, mean a child shouldn’t be discharged home. This is a large retrospective study from 2 academic pediatric hospitals, looking at 97,824 emergency department visits, of which 83,092 resulted in discharge. (This is a very high admission rate, consistent with the fact that these are pediatric tertiary care hospitals, and so the children being seen here are much sicker than I see in my community hospitals.) Of the 83,000 discharges, 17,661 (21.3%) had abnormal vital signs at the time of discharge. So lesson number 1: it is the standard of care to discharge patients home with abnormal vitals. They are doing it more than 20% of the time in tertiary pediatric hospitals. The primary outcome of the study was ED return visits, and it was identical whether you had abnormal or normal discharge vital signs (2.45% vs 2.26%). Only about ¼ of the ED return visits resulted in admission to hospital, so most of these children still weren’t sick (a return visit is not necessarily a bad outcome). There is one massive problem with this study: they included temperature as an abnormal vital sign. No one cares if the child is febrile when you are sending them home. We don’t expect that to be related to bad outcomes. It is the tachycardia or tachypnea that we are worried about. In fact, I think this biases the trial towards finding more return visits in the ‘abnormal vital signs group’ because we specifically tell febrile children to come back if their fever hasn’t resolved by day 5. Those return visits aren’t markers of bad outcomes. They present data suggesting this is the case, because the only vital sign that was associated with return visits was temperature. I’ll say that again: none of heart rate, blood pressure, respiratory rate, nor oxygen saturation were associated with return visits to the emergency department. If you want to really dissect this data, in children less than the age of 3 and children whose initial triage category was high, the discharge vital signs were associated with return visits and hospitalizations, so be somewhat more cautious in those groups. Of course, all this data is limited by the fact that it is retrospective, but vital signs are at least consistently recorded in the EHR. I think this is a really important lesson to learn. You shouldn’t be cavalier about vital signs. Abnormal vital signs should make you pause, perhaps re-examine the patient, and provide good discharge instructions. But you simply cannot practice good pediatric medicine if you are scared of sending kids home with abnormal vital signs on the chart. Every few years this topic comes up because of a miss; a child will be diagnosed with myocarditis, and they will look back at the emergency visit and find she was tachycardic, and try to implement some ridiculous rule that tachycardic children should never be sent home. However, they never look at the 10,000 other charts of tachycardic children who were sent home with no problems at all.
Bottom line: This retrospective dataset illustrates that a very large number of pediatric patients have abnormal vital signs at the time of discharge, and those abnormal vitals signs were not associated with an increase in return visits.
This one just scared the hell out of me
Chandran V, Sekar A, Mishra N. Transoral fractureless penetrating injury to brainstem in a child: a rare presentation. Childs Nerv Syst. 2022 Mar;38(3):505-507. doi: 10.1007/s00381-022-05455-1. Epub 2022 Jan 28. PMID: 35091807
This isn’t evidence based medicine, and there may not be a lot to learn from this case presentation, but this paper stopped me in my tracks. Sometimes it is good to spend some time flexing your brain, and thinking through plans for difficult resuscitations that you will hopefully never see. An 18 month old tripped and fell with an object in her mouth, and this is what comes into the ED:
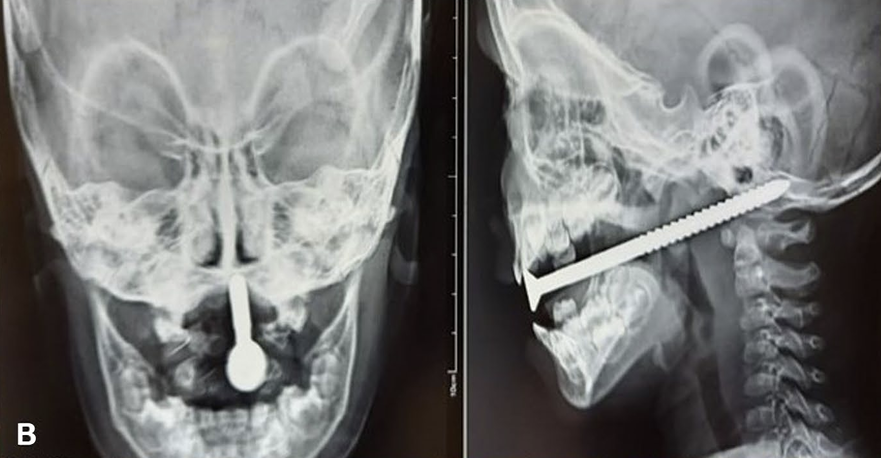
She is alert, has spastic weakness of the right limbs, but obviously is too distressed to co-operate with any more evaluation. I believe, based on the description, there was no active bleeding and no signs of airway obstruction. Aside from simply needing to share my misery in happening across this case, I share it so we can all reflect on our management of a very challenging pediatric airway. Aside from changing your underwear, what is your plan? The case will be discussed with my pod-cast co-host, and expert remote setting anesthesiologist, Casey Parker, so be sure to check out the BroomeDocs podcast for some discussion.
If it makes you feel better, it sounds like this child had a pretty good outcome. There was some mild weakness on the left side of the body immediately postoperatively, but the child was tolerating oral feeds by post-op day 5, and the weakness improved with rehabilitation.
Maternal kisses are not effective in alleviating minor childhood injuries (boo-boos)
Study of Maternal and Child Kissing (SMACK) Working Group. Maternal kisses are not effective in alleviating minor childhood injuries (boo-boos): a randomized, controlled and blinded study. J Eval Clin Pract. 2015 Dec;21(6):1244-6. doi: 10.1111/jep.12508. Epub 2015 Dec 29. PMID: 26711672
As any long time reader will know, I tend to shy away from topics that might be controversial. However, this paper was too important to avoid, despite the potential ensuing controversy. Just remember, I am the messenger, and not the scientist nor the creator of the orders and laws of the universe. To set the stage, allow me to quote from the article: “The use of maternal kisses in the treatment of minor injuries occurring in early childhood (boo-boos) predates the era of evidence-based medicine by at least several decades. As such, controlled studies of maternal kissing are rare and, in general, poorly designed… Nonetheless, maternal kissing of infants and toddler boo-boos continues to be a common first line therapy. According to the US Census Bureau, fully 97% of American mothers admitted to kissing at least one minor childhood injury in 2010… Such widespread endorsement of an unproven intervention bespeaks the untoward propensity of doctors (at least American doctors) to accept tradition, magical thinking and expert opinion as a foundation for clinical practice.” This is a multi-centered, multidisciplinary, blinded, randomized controlled study in which 943 mother-toddler pairs were enrolled. To be included, mothers had to “have two lips sufficient in nature to deliver a palpable kiss.” I am somewhat concerned that ethics review is not mentioned in the paper anywhere, as children were injured intentionally in this study! “To induce head boo-boos, a piece of chocolate was placed under a low table edge and the child would be allowed to crawl to the candy. Invariably, the child would then stand to eat the chocolate and would strike his or her head on the table edge.” Alternatively, “Hand boo-boos were induced by placing a favourite object (lovey) of the child just out of reach on a counter behind a heated coil. Attempts to obtain the lovey would result in a noxious thermal stimulus to the fingertips. The coil was heated to 50 degrees Celsius (120 F) in order to produce a significant but non-damaging stimulus.” (I picked this paper because it sounded funny, but this is the point I became borderline terrified.) Children were randomized to either a maternal kiss of the injured body part, a non-maternal kiss (sham), or nothing. The kisser was behind an opaque screen, so the children were blinded to their identity. As testimony to the cruel and unethical nature of this study, although all participants were supposed to come back for 2 sessions to test 2 different therapies, 512 (of 943) did not return. Thus, in total there were 1374 injuries. Based on the toddler discomfort index, all groups had the same amount of pain at one minute. There was no difference between a maternal kiss and a kiss from a stranger, but both kiss groups were better than nothing at 5 minutes. (Now you can see the biased reason I wanted to include this study. As a father, it is essential I prove there is nothing special about mom’s kissing, and that I am an adequate substitute.) Some conversation points from the paper: “First, the placing of the lips on the soiled appendages of toddlers likely puts mothers at a higher risk of acquiring viral and bacteriologic infections. Second, maternal resources are very limited, and time spent on delivering ineffective kisses to boo-boos means that maternal attention is not devoted to other activities that have clearly been shown to be beneficial to toddlers, such as the introduction of algebraic functions and the teaching of conversational Mandarin.”
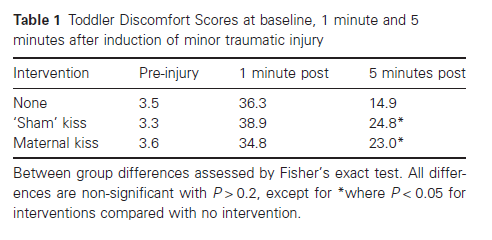
Bottom line: Even if your study is for fun, it needs to pass an ethics review. It makes sense that nobody was brave enough to put their real name on this publication.
How nice is your car?
Richardson, Daniel C., et al. “Small Penises and Fast Cars: Evidence for a Psychological Link.” PsyArXiv, 10 Jan. 2023. Web. https://psyarxiv.com/uy7ph
Long suspected, but now we apparently have evidence to prove it: penis size is correlated with vehicle choice. The study is available only as a preprint, but this seems like the kind of essential scientific data that is worth rushing to discuss prior to peer review. Because self-reported penis size is “notoriously unreliable”, these researchers influenced men’s feelings about their own penis by giving them false information about the average penis size, mixed in with other information. (I will say that both sizes they list – 10 and 18cm – sound pretty small to me.) They weren’t assessing the actual purchase of sports cars, but rather the ratings men gave those cars, which is a big limitation if you are trying to assess a person’s anatomy based on their car. The effect varies by age, such that all young men like sports cars, and ratings for sports cars remains high if you think you have a small penis, but not if you think you have a large one. Sorry for such a short summary on what might be the most important topic of the month, but I figure people will want to read this and form their own opinions.
Poem of the Month (Trust me)
When Odysseus finally does get home
he is understandably upset about the suitors,
who have been mooching off his wife for twenty years,
drinking his wine, eating his mutton, etc.
In a similar situation today he would seek legal counsel.
But those were different times. With the help
of his son Telemachus he slaughters roughly
one hundred and ten suitors
and quite a number of young ladies,
although in view of their behavior
I use the term loosely. Rivers of blood
course across the palace floor.
I too have come home in a bad mood.
Yesterday, for instance, after the department meeting,
when I ended up losing my choice parking spot
behind the library to the new provost.
I slammed the door. I threw down my book bag
in this particular way I have perfected over the years
that lets my wife understand
the contempt I have for my enemies,
which is prodigious. And then with great skill
she built a gin and tonic
that would have pleased the very gods,
and with epic patience she listened
as I told her of my wrath, and of what I intended to do
to so-and-so, and also to what’s-his-name.
And then there was another gin and tonic
and presently my wrath abated and was forgotten,
and peace came to reign once more
in the great halls and courtyards of my house.
By George Bilgere



