
Morgenstern, J. Clinical decision rules are ruining medicine, First10EM, February 2, 2023. Available at:
https://doi.org/10.51684/FIRS.129162
This evidence review is the handout for the talk I gave at the Emergency Medicine Cases Summit entitled “Decision rules are ruining medicine”.
Clinical decision rules (CDRs) sort of suck
There is a common assumption that clinical decision rules must improve decision making and clinical care. This is based on the fact that clinical decision making (like all human decision making) is flawed, subject to many biases, and highly variable. However, this assumption is unproven, and probably not consistent with what we know about clinical decision rules.
Some rules aren’t even validated
Perhaps the most egregious example I have seen in widespread use is the RASP score for HIV needle stick assessment. I was taught this score and I have used it with many patients. However, in preparing for this article, I discovered that this score might not have any science behind it at all. It might not even have been derived, let alone validated. The only citation I can find for this score is Vertesi 2003, which describes the score and how to use it, but gives no details about how it was created and has no citations. As far as I can tell, the score was just made up.
Most examples aren’t as egregious as the RASP score. Usually, a new rule will be derived and have an internal validation at the same research site, but lack the external validation required to ensure generalizability. However, we have a history of adopting these rules before validation studies. For example, the PECARN head rule was widely used before any validation study was published. Likewise, people are already recommending the use of the PECARN rule for low risk febrile infants despite the lack of any external validation. Sometimes clinicians are overly eager and rush to implement rules before they are ready. Other times, the necessary follow-up research never occurs. For example, Ranson’s score for pancreatitis appears to only have been derived without internal or external validation, so despite being around for decades, it is not clear that its use is at all appropriate. (Ranson 1974)
In medicine, we are always working with imperfect evidence. In that context, these scientific gaps might not seem too bad. However, the apparent objectivity and precision of decision rules is problematic. There are no confidence intervals when I look up the RASP score on MDCalc. There is no indication the numbers might be wrong. I am just presented with a specific, seemingly objective number, which actually might not have any basis in reality. That is a problem.
Decision rules aren’t better than doctors (or we don’t know if they are)
In order to assess the value of any new diagnostic test, we must compare it to the current gold standard. In the case of clinical decision rules, the current gold standard is clinical judgement or usual care. Most rules have never been tested against this gold standard, and the majority of those that have been aren’t better than clinical judgement.
“Before widespread implementation, CDRs should be compared to clinical judgement.” (Finnerty 2015)
Dave Schriger and colleagues reviewed publications in the Annals of Emergency Medicine from 1998 to 2015 to determine how many clinical decision aids had been compared to clinical judgement. (Schriger 2017) (They mix both formal decision rules and individual tests meant to help with clinical decisions.) Only 11% (15 of 131) of the studies compared decision aids to clinical judgement, so for most decision aids we just have no idea how they compare to basic clinical assessment. In those that did compare to clinical judgement, physician judgement was superior in 29% and equivalent or mixed in 46%. The decision aid only outperformed clinical judgement in 10% of papers (or 2 total trials). I imagine this is an overestimate, as the 90% of trials that don’t report this comparison are clearly conflicted, benefiting from promoting their decision rule, and are therefore less likely to publish a negative comparison. Furthermore, just because a single study concludes that a decision rule is better than clinical judgement doesn’t mean that conclusion is correct. Therefore, even this 10% number is likely a drastic over-estimate.
In a similar study, Sanders and colleagues performed a systematic review of studies that compared CDRs and clinical judgement in the same patients using an objective standard. (Sander 2015) Oddly, they decided to exclude RCTs comparing CDRs to clinical judgement, which would actually be the best form of evidence, because they wanted the two to be compared in the exact same patients, rather than in 2 random groups. They found 31 trials, including 9 looking at PE, 6 for DVT, 3 for strep throat, 3 for ankle and foot fractures, 2 for appendicitis, and then single trials for a number of other conditions. In total, 25 different CDRs were evaluated (probably indicating that the vast majority of CDRs don’t have data comparing them to clinical judgement.) The results are somewhat hard to summarise, because they compare both sensitivity and specificity, and the results can be worse, equal, or better. There was not a single case where a CDR was better than judgement in both sensitivity and specificity, but clinical judgement did win on both accounts in 1 study. In the majority of cases, CDRs were equivalent to clinical judgement. When there was a difference, benefit was frequently offset by harm. That is, the CDR might decrease false negatives, but at the cost of increased false positives. The authors conclude that clinical decision rules “are rarely superior to clinical judgement and there is generally a trade-off between the proportion classified as not having disease and the proportion of missed diagnoses.”
Looking at a few specific examples
The Well’s score for pulmonary embolism is the best studied CDR, but unfortunately most of the comparisons occur in an inpatient setting with higher rates of PE, so are not directly applicable to us in the ED. For what it’s worth, clinical judgement seems to be equivalent to or outperform the Well’s score. (Sander 2015) In 89% of cases, clinical judgement was just as sensitive, and specificity seems to be about equal or better. In the other 1 study (11%), clinical judgement was more sensitive but equally specific when compared to the Well’s score.
The Ottawa ankle rule has the best evidence, as compared to clinical judgement. (This makes sense, because if rules are likely to help, they will be at the best in answering simple questions like ‘is there an ankle fracture?’) It has been compared with clinical judgement in 3 studies. There is one study in which the Ottawa ankle rule outperformed clinical judgement, but it only included 18 patients and the clinicians sent everyone for x-ray, so it doesn’t seem like they were applying much judgement. (Singh-Ranger 1999) Another study of resident physicians found that the Ottawa ankle rule was marginally more sensitive (89% versus 82%, not statistically different) but far less specific (26% vs 68%) than clinical judgement. Use of the rule would have resulted in more x-rays. Both the Ottawa rule and judgement missed 1 clinically significant fracture. (Glas 2002) The final paper is a prospective observational trial in 80 children, 21% of whom had a fracture. (Al Omar 2002) The Ottawa ankle rule was 100% sensitive and 30% specific. Clinical judgement was 64% sensitive and 76% specific. They don’t discuss the importance of the physicians’ misses. Although this data does suggest that the Ottawa ankle rule outperforms clinical judgement in terms of sensitivity, there is a clear trade off in specificity. However, because it has been so widely used, my guess is that the Ottawa ankle rule is now completely part of everyone’s clinical judgement, and if this comparison were replicated, clinical judgement is likely now at least as good as the CDR. (This is probably the primary argument for clinical decision rules. They might be able to get us to the same starting point. However, it also suggests a major problem with the current research paradigm: our practice will change as we learn these rules, so we really need follow-up studies many years later to see if the rules still help after clinicians have incorporated the components of the rules into clinical judgement.)
The other clinical decision rule that compares somewhat favourably to clinical judgement is the Canadian CT C-spine rule. This is probably in part because it again asks a relatively simple question, but mostly because in the case of C-spine injuries we are willing to sacrifice specificity for sensitivity. In the CCC study, the Canadian C-spine rule had a sensitivity of 100% and a specificity of 44%. Physician judgement (using a 5% threshold as their definition of low risk, which might bias these numbers as many doctors would still image at a 5% risk) had a sensitivity of 92% and a specificity of 54%. There are three important aspects to this data. First, like always, we are trading specificity for sensitivity. (Although the AUC of the decision rule is also somewhat better.) Second, we could make the physician’s judgement more sensitive if we used a lower cutoff (ie, required the doctor to think there was less than 1% chance of an injury to forgo imaging). Finally, clinical judgement in one group of doctors does not necessarily translate to others. These were Canadians practising more than 20 years ago. I can almost guarantee that physicians practise more conservatively in almost every practice setting in 2023, and so clinical judgement might look very different if it were to be studied again today.
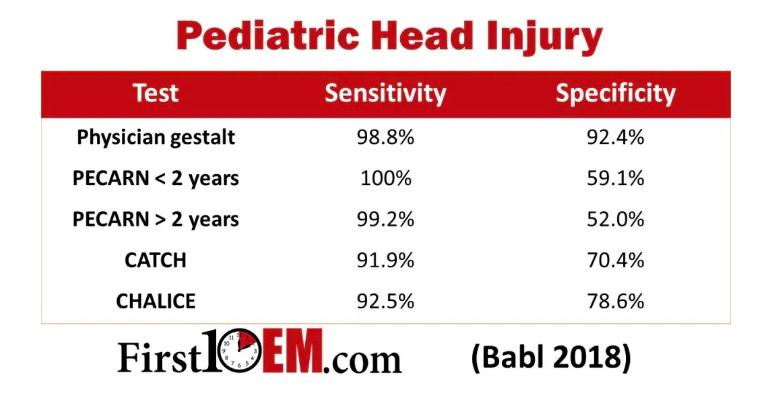
For paediatric head injury, clinical judgement outperforms clinical decision rules. (Babl 2018) As discussed here, clinical judgement matches PECARN in sensitivity for important injuries, but is vastly more specific. In other words, use of PECARN would result in more imaging without a statistical difference in the miss rate. I don’t think anyone uses CATCH or CHALICE anymore, but there isn’t even a comparison: both are far worse than clinical judgement. Both would have doubled or tripled the CT rate while simultaneously having more misses. At one point, both of these rules were used in clinical practice, which is an excellent example of why we should not implement decision rules until they are proven in implementation studies.
I have never used a clinical score for appendicitis, nor have I ever seen it recommended in Canada, but I know they are used in some places. The Alvarado score is worse than clinical judgement in excluding appendicitis, with a sensitivity of 72% as compared to 93% sensitivity of unstructured clinical judgement. However, there is a tradeoff, in that clinicians are much less specific. (Meltzer 2013)
One study reported that the STONE score is better than physician gestalt in the diagnosis of kidney stones, but this was based solely on a statistical difference in AUC that doesn’t seem like it would translate to clinical benefit. (Wang 2016) The sensitivity and specificity of the STONE score above 10 was 53% and 87% respectively. For physicians’ judgement, looking only at the group where the physicians thought the chance of stone was greater than 75%, the sensitivity and specificity were 62% and 67%. However, these numbers are artificial, because neither was assessed as a yes/no question. There are multiple other cutoffs that can be chosen. For example, if you look at physicians’ judgement in the group they thought there was more than a 50% chance of a stone, the sensitivity is 85% and specificity is 42%. Clinically speaking, it doesn’t really seem like the STONE score improves on clinical gestalt – at least not in a way that can be clinically applied.
As compared to current physician gestalt, the PECARN abdominal trauma rule missed more injuries (it missed 6 as compared to only 1 missed by physician gestalt). (Holmes 2013) The rule’s specificity was significantly better, but seeing as the rule is designed to be a one way rule, the specificity shouldn’t actually matter, and so I think this counts as being worse than clinical judgement.
Rules derived from gestalt won’t beat gestalt
This is a subtle, but important point. Clinical decision rules are often created by codifying gestalt, which means they will always be lesser than gestalt.
Sometimes, rules are created entirely from gestalt, without even undergoing a derivation step. The step-by step rule for febrile infants, the HEART score, the APGAR score, the APACHE score, and the mini-mental state exam are all examples of clinical decision aids that were made up by experts rather than being derived. However, even when a rule is created through the standard derivation process, it is often just a codification of clinical gestalt. If at the beginning of your methodology you ask experienced doctors what factors should be considered, and then run stats to figure out which are the most important, your entire scientific process is aimed just at determining which components of clinicians’ gestalt are the most impactful. Because the ultimate decision rule will eliminate some clinical features that clinicians were considering, the rules will almost by definition be worse than judgement.
In other words, the derivation of many rules starts with our clinical gold standard of clinician judgement, and then pares down from there. It is possible that such a rule could beat clinical judgement, if it helps us appropriately weigh the importance of clinical features, or helps us remember all important factors, but it is going to be very difficult for a subset of clinical judgement to beat total clinical judgement. This is why it is absolutely essential that every rule be compared to clinical judgement before we even consider using it clinically.
Other rules attempt to add to gestalt, which is theoretically better. For example, the Well’s score for PE explicitly asks for our gestalt, and then adds some other factors that presumably could fine tune our judgement. However, anyone who has used the rule knows that the outcome almost always comes down to the dichotomous decision about whether PE is the most likely diagnosis. Worse than that, the way most of us determine whether PE is the most likely diagnosis is to consider the risk factors in the score, which are therefore not independent variables, which probably explains why the score doesn’t improve on gestalt. (Sander 2015)
Bottom line
Almost none of our decision instruments have been compared against what should be considered the gold standard: current practice or clinical judgement. Of those that have, almost none are superior to clinical judgement. This should be the minimum standard for clinical decision rules. If they are not better than your current judgement, then they provide no benefit.
Although comparison to clinical judgement is often tacked on to later phases of research, that approach makes absolutely no sense. Decision rules should never go through the derivation and validation stages without simultaneously being compared to the current gold standard: clinical judgement. Leaving out this comparison can only cause harm and waste in unnecessary future research. Funding bodies and research ethics boards should not approve clinical decision rule research that doesn’t include a comparison to clinical judgement as the gold standard.
Rules are often overfit or overly optimistic
Most rules look worse on external validation than they do in the initial publication. I don’t want to get into the many different statistical methods that can be used to derive decision rules (because then I would have to admit that I don’t fully understand them), but there are statistical reasons that a rule will often look better in the population from which it was derived. This is called being statistically “over-fit” to the data. All that really matters is that we see the rule validated in multiple populations.
We have many examples of clinical decision rules that deteriorate with subsequent study. (Often these rules are transformed into new versions. Every time you see a new version of a score, such as the ABCD2 score as compared to the ABCD score, you should be reminded that the original failed). The initial derivation and internal validation of the San Francisco Syncope score demonstrated sensitivities of 96-98%. (Quinn 2004, Quinn 2006) However, 3 external validations were only able to demonstrate sensitivities closer to 90%, (Cosgriff 2007, Sun 2007, Thiruganasambandamoorthy 2010), and another showed a sensitivity of only 74% (Birnbaum 2008), and so we eventually abandoned the rule. This is a relatively common pattern.
However, even without statistical overfitting, there are other reasons that rules can be overly optimistic. I think the most important is the inclusion of inappropriate patients in the research.
We need decision rules that help us with truly undifferentiated patients. We don’t need rules to help us when patients have an obvious diagnosis. However, these obvious patients are often included in decision rule studies, and can make the rules look better than they really are. (This is similar to the reason that BNP doesn’t help. On paper, it sometimes looks great, but all the patients it identifies were clinically obvious.)
Consider the HEART score. Although they excluded STEMI patients, they included patients with clear ischemic ST depressions in the study cohort. (Six 2008) Do you need help determining the disposition of people with ischemic ECGs? Obviously not, but the score gets credit for everyone one of these patients that it classifies as high risk. By including the ‘low hanging fruit’, the specificity is artificially inflated, but we would never apply the score to these patients clinically. At the opposite end of the spectrum, patients with clear non-cardiac chest pain were not excluded. You could have a 20 year old with clearly MSK chest pain after a fall, who none of us would ever consider working up for ACS, being included and counted as a ‘win’ for the HEART score because he was correctly classified as low risk. Including patients who are obviously positive or negative in the research cohort artificially inflates the sensitivity and specificity of the rule.
For a numerical example of this phenomenon, we can look at the paper by Sun (2007) looking at the San Francisco syncope rule. Overall, they found that the rule had a sensitivity of 89%. However, almost all of the adverse events were clinically obvious, occurring during the initial ED stay, rather than occurring after discharge (which is what we need the rule for). If you eliminate those patients, the rule only has a sensitivity of 69%.
Bottom line: It is essential that rules are derived and validated in the same population in whom the test will be applied clinically in order for the reported test characteristics to be applicable.
Rules don’t improve practice (or we don’t know if they do)
Simply being better than (or even as good as) clinical judgement is not enough. The point of decision rules is to improve practice. After derivation and validation (which give us a sense of diagnostic characteristics like sensitivity and specificity), decision tools need to go through implementation or impact studies in order to demonstrate the impact they have on patient outcomes when introduced into clinical practice. This is the most important step of decision rule development, but it is almost never done.
Some rules seem to cause harm
The Canadian CT head rule is one of the few decision rules to be tested in an RCT, and it looks like it might cause harm (and definitively does not help). (Stiell 2010) The point of the decision rule is to decrease CT usage. In a cluster randomised trial, in which the rule was implemented in 6 emergency departments and compared to 6 control sites, the use of CT significantly increased after implementation of the rule, from 63% in the before period to 76% in the after period (absolute increase 13.3%, 95% CI 9.7-17.0%). CT usage in the control hospitals also increased (from 68% to 74%, difference of 6.7%, 95% CI 2.6-10.8%). The increase was not statistically different between the two groups (p=0.16), but the rule clearly did not succeed in improving clinical practice, and if anything looks like it makes things worse. This is in a best case scenario, where people were being trained on the rule and knew they were being watched. In real life, I think everyone knows this rule dramatically increases CT use, as the general understanding in modern medicine seems to be that you must CT everyone over the age of 65. Personally, I think it is pretty clear that the Canadian CT head rule has made modern emergency medicine practice worse.
Some rules only seem valuable because of the population in which they were tested
When you hear that a clinical decision rule has been proven to improve practice, it is essential to ask: whose practice? (I love Americans for many reasons, but their medical system results in such a bizarre skewing of clinical decisions that rules tested there are unlikely to be applicable in other scenarios.)
For example, in a setting with an astronomically high baseline rate of CT scan for paediatric head injury, implementation of the PECARN rule might help. In one setting, with a baseline CT rate of 21% (despite a clinically important traumatic brain injury rate of 0.2%), the PECARN rule decreased CT usage to a still ridiculously high 15% in a before and after QI study. (Nigrovic 2015) However, the practice in this setting was so clearly inappropriate, I don’t think PECARN is the real answer. Any QI intervention, especially if implemented in a formal (and therefore legally protective) fashion, might have succeeded. However, the PECARN rule completely fails in a population with even moderate to high CT usage. In an Italian study with a baseline CT rate of 7.3%, implementation of PECARN resulted in CTs being ordered 8.4% of the time (not statistically different) with no change in the miss rate. (Bressan 2012) Personally, I think this CT rate is still very very high (at least an order of magnitude higher than CT usage in my practice), which means that implementation of PECARN in the settings where I work is very likely to increase CT usage (ie, cause harm).
Although the HEART rule has not been studied in an implementation trial, a modified version called the HEART pathway has been. (Mahler 2015) (I am not sure where a rule that was not derived or validated, but was tested in an RCT, fits into the hierarchy of science). The HEART pathway decreased the use of 30 day cardiac testing from 69% to 57%. However, considering that 47% of this population had a HEART score less than 3 and negative serial troponins, and the fact that there is no benefit from stress testing at all, the baseline testing was almost certainly much too high. If implemented in my practice, the HEART pathway would dramatically increase testing, almost certainty harming my patients.
Real versus potential impact
It is also important to consider the difference between potential impact and real impact. When testing drugs, we talk about pragmatic trials versus explanatory trials. When we control every aspect of a trial, we can demonstrate the efficacy of a drug under ideal conditions that are never met in the real world. The value of pragmatic trials is they demonstrate the true impact of a drug as it would be used in real world settings. This distinction also applies to decision rules. When being studied at the academic centres in which they were developed, there are likely multiple forces in place to ensure people are using the rules perfectly. However, we know the rules will be used imperfectly in the real world, either through misunderstandings, or because clinicians will occasionally decide to overrule the rule, and it is the real world impact that really matters to patients.
For example, there is an RCT demonstrating the value of the Well’s score in conjunction with DDimer for decreasing ultrasound use for DVT. However, in the main RCT physicians were required to use the rule, so we are unsure how it might work in a real world setting, where clinicians might ignore the rule, or apply it selectively. (Wells 2003)
There is a study of a chest pain triage rule which demonstrates this. If the rule had been strictly followed it would have significantly decreased resource utilisation, but physicians frequently ignored or overruled the rule, making it significantly less effective (but maybe safer). (Reilly 2006)
Perhaps the best example of this concept is the Ottawa ankle rules. In the initial implementation study, they demonstrated a significant reduction in x-ray use when the rule was implemented. (Stiell 1994) However, the hospital being studied was the academic centre where the rule was developed, and therefore motivation to apply the rule may be higher than we would see in the real world. In a follow-up before and after study that looked at an active implementation of the rule in 10 hospitals through a dedicated education series, there was no change in x-ray use. (Cameron 1999) (Actually, x-ray usage increased by 5% in the after period, 73% vs 78%, p=0.11).
Even clinical decision rules that have positive implementation studies may not actually help your patients. Like all scientific research, these positive studies need replication. There are many reasons that initially positive studies (which are often performed by the researchers promoting the rules) may not pan out when externally replicated.
Bottom line
We really shouldn’t be using any decision tool until it has been shown to improve patient outcomes in an implementation study.
“Although multicenter validation of a CDR may provide support for implementation, impact analysis ultimately serves as the reference standard for assessing clinical significance and utility.” (Finnerty 2015)
The ideal form of impact study is the randomised control trial. Because it is almost impossible to randomise individual patients (because their clinicians will have already learned the rule), this is often done as a cluster randomised trial. Before and after trials are also used, but subject to much greater risk of bias. I would not implement a rule based solely on a before and after study, but if an RCT already existed, the before and after study might be a reasonable way to provide external validation to alternate populations.
Decision rules with RCTs or controlled trials demonstrating real patient value:
- Ottawa ankle rule decreases radiography (although the trial wasn’t actually randomised). (Stiell 1994). However, there is conflicting data, and follow up research indicated no impact at all. (Cameron 1999)
- Ottawa knee rule decreases radiography (not randomised, before-after trial, but with control hospitals). (Stiell 1997)
- Canadian c-spine rule decreases imaging. (Stiell 2009)
- Well’s score plus DDimer decreases ultrasound use (but increases blood work). (Wells 2003)
- PERC decreases CTPA use with no change in the miss rate. (Freund 2018)
- YEARS plus age adjusted Ddimer decreases imaging use when compared to age adjusted Ddimer alone, without increasing misses. (Freund 2021)
(1. This list may be incomplete, as it is a difficult search to perform. 2. An RCT may report value even if that value is unlikely to be true. 3. This list is based only on abstract conclusions, and therefore certainly an over-estimate. If you start reading these papers, you will see that the evidence supporting the rules is often much weaker than you might expect.)
I didn’t count the HEART pathway here, although there is an RCT, because the pathway was not derived and validated before the RCT. It was just made up and put in an RCT.
Most people don’t think of the age adjusted D-Dimer as a clinical decision rule, but it fundamentally does the same thing as decision rules. It has been shown to be helpful in an RCT setting. (Righini 2014) I mostly include this to demonstrate that RCTs are possible in these diagnostic questions, and the same methodology could be used in almost all of the CDRs listed below with no evidence of clinical impact.
Commonly used rules without controlled trials demonstrating patient value**: NEXUS, Wells score PE, PECARN head, PECARN febrile infant, Step by Step, PECARN abdominal, CATCH, CHALICE, ABCD2 score, Aortic Dissection Detection Risk Score, APGAR score, Canadian Syncope Risk Score, Canadian Transient Ischemic Attack (TIA) Score, CHADS2 score, EDACS (there is one RCT, but only against another decision rule, not a real control group), Glasgow Coma Scale, HAS-BLED, RASP, qSOFA, LRINEC, Kocher Criteria for Septic Arthritis, Injury Severity Score, Ottawa Subarachnoid Haemorrhage (SAH) Rule, Ottawa COPD Risk Scale, Pneumonia Severity Index, Ranson’s criteria for pancreatitis, Rochester Criteria, San Francisco Syncope Rule, STONE score TWIST, 4PEPS.
Commonly used rules with controlled trials demonstrating a lack patient value**: Canadian CT head
(**Again, these lists may be imperfect. Sometimes these rules are tested within bundles. For example, I remember an RCT demonstrating a mortality benefit of a pneumonia bundle which might have used CURB-65, but the paper didn’t come up in my literature search. If you think a rule is misclassified, let me know. Furthermore, this list is not meant to be exhaustive. There are literally hundreds of rules. The point is that almost none of them have been proven to help our patients.)
Many decision rules are just insulting
The classic example is the qSOFA rule. (Seymour 2016) People have spent a lot of time talking about statistics. They have focused on sensitivity or specificity. None of that is necessary, because just reading the rule tells you that it can’t possibly outperform a doctor, unless you really think that doctors are dumb as dirt.
As a reminder, the qSOFA rule asks you to consider three parameters: is there altered mental status (GCS <15), is there tachypnea (respiratory rate over 22), and is there hypotension (systolic BP 100 or less)? If you have 2 of these features you are considered high risk. If you even pause for a second, it is clear that this rule is stupid. A patient who is hypotensive and altered is high risk. A patient who is hypotensive and tachypneic is high risk. A patient who is tachypneic and altered is high risk. Does any clinician need a rule to help identify these high risk scenarios? I don’t think this rule could even improve the judgement of lay people. It says that sick people are sick, and is just a waste of everyone’s time.
Most people noticed this problem with the qSOFA score, but many of our most beloved rules are similarly problematic when you really think about them. Personally, I love the Ottawa ankle rule. (Stiell 1993) It is simple, easily applied, and one of the very few rules that has actually been shown to potentially improve practice in implementation studies. (Stiell 1994; Stiell 1995) However, when you actually pause to think about it, the Ottawa ankle rule is pretty insulting. Or, if not insulting, perhaps just a condemnation of medical education. Think about what the rule says. It tells us that you might have a broken ankle if you can’t walk, or if you have pain when we push on your bones. It says you are unlikely to have a break if you can walk and it doesn’t hurt when we push on your bones. I don’t think we needed a rule to teach us that. I don’t think you even need medical school for this one. I bet a highschool student could have sorted this out. The idea that we need a rule to tell us to push on the bones to see if they hurt is pretty insulting.
This section might be redundant. Really, it is just another way of saying that rules need to be better than clinical judgement if we are going to use them. However, I think this alternative perspective is important. Superficially, rules often seem objective and concrete. I think it is important to scratch at their surface, because often even our best rules – like the Ottawa ankle rule – are (insultingly) basic re-packagings of clinical judgement.
Superficial objectivity
One of the key advantages of decision rules is that they are supposed to standardise care. They are supposed to provide objective numbers on which we can base our decisions, rather than the ‘horribly subjective clinical judgement’ of physicians. However, their objectivity is often largely for show.
Sometimes the subjectivity is built right into the rule. The HEART score asks how suspicious the story is based on your subjective judgement. The Well’s score asks you if you think PE is the most likely diagnosis. The rule spits out a seemingly objective number, masking the clear subjectivity within the rule.
However, frequently the subjectivity is hidden. Not all researchers report on it, but the inter-rater reliability of the individual components of scores is often very poor, which means the rules are inherently subjective.
The NEXUS c-spine rule is one of the simplest rules we use, and it seems relatively objective when applied. However, when staff physicians were compared with resident physicians, they disagreed on each individual criteria between 5 and 15% of the time, which adds up to an overall disagreement of 23% about whether the rule was positive or negative. (Matteucci 2015)
Many studies have assessed the inter-rater reliability of the HEART score. You would expect the history component to be poor, and you would be correct, with kappas between 0.1 and 0.66 (which is very bad). However, ECG also has poor agreement, with kappas as low as 0.31, and we can’t even agree on how many risk factors patients have (kappas from 0.43-0.91). Even age and troponin positivity didn’t have perfect agreement among doctors! As a result, our agreement on the overall score, or even whether a patient is in the low risk group, is moderate at best. In fact, agreement on the total score is only between 29 and 46%, meaning that if you see two different doctors, it is more likely than not that you will get 2 different scores. (Green 2021)
Unfortunately, data about intra- and inter-observer reliability is often lacking. In one review of 32 CDR publications from major journals, only 1 reported on the reproducibility of the individual predictor variables, and none commented on the reproducibility of the rule itself. (Laupacis 1997)
Another important, but often overlooked, source of subjectivity in clinical decision rules comes from inclusion and exclusion criteria. The step-by-step rule applies to “well looking infants”. (Mintegi 2014) PERC is only supposed to be used after a low clinical gestalt, or the Well’s score which includes subjective assessment. (Kline 2004) NEXUS was applied to patients in whom the treating physician subjectively believed imaging of the c-spine was necessary. (Hoffman 2000) In addition to the significant subjectivity found within rules, there is a layer of subjectivity about which patients should have them applied.
The superficial objectivity of decision rules is fundamental to their (mis)use in modern medicine. Governing bodies love to be able to point to a seemingly objective score when assessing clinical practice. Lawyers love it if our practice seems to deviate from these seemingly objective scores. If the outcomes of these rules are considered objective, they can be used to set the standard of care. But the outcomes of the rules are not objective; they are only superficially so. It is all a facade. Clinicians are therefore judged against a false standard. We are forced to shift our practice away from good clinical judgement, towards bad – but superficially objective – rules. As a result, medicine suffers. More specifically, our patients suffer.
Clinical decision rules often ignore the fundamentals of diagnostics
Very few decision rules adhere to the basic rules – or mathematics – of diagnostics. These are rules we are all taught in medical school. We all know Bayesian reasoning. (OK, after being called out here, I will rephrase to say we all should know Bayesian reasoning.) We all know that 0% and 100% probabilities are impossible; and yet time and again decision rules are designed with the goal of 100% sensitivity. This quixotic task is divorced from reality and ultimately harms patients.
A good decision rule should start within the threshold framework. It should have a clear target, based on the test threshold, below which further testing is not necessary (or, more correctly, would be harmful). Or, they should have a clear target, based on the treatment threshold, above which testing is not necessary, but treatment should be provided.
Almost none of our decision rules start with a clear realistic target. Without a clear target, it is impossible to truly assess whether these rules are succeeding in their validation phase. Unlike PERC (which is a good example of using this approach), rules frequently just present their outcomes without stating a target. The low risk population in an initial derivation and validation study might have a miss rate of 1%, which we might accept because it sounds suitably low. But without a target, how do we know if external validations succeed? What if the external validation has a miss rate of 1.5%, or 2%? What if the 95% confidence intervals extended to 3%? Is that good enough? Unless you set a specific target at the outset, we don’t have a clear criteria on which to judge subsequent validation studies.
For example, in the initial study of the HEART score, patients with a low risk score had a 2.5% risk of MACE. (Six 2008) However, the test threshold for MACE was never calculated, so it is impossible to know whether this is a good or bad outcome. More importantly, it is very difficult to assess the subsequent validation studies. How do we know the outcomes are really equivalent? Should subsequent studies be within 5% of each other? 2%? 1%? In a follow-up cohort, the rate of MACE was 0.99% in the low risk group. (Backus 2010) In another study, the rate was 1.7% (but they don’t report the 95% confidence intervals). (Backus 2013) Those numbers sound great, but do they count as ‘validation’? How far off could have they been, while still reflecting a successful replication of the initial dataset? Without knowing the test thresholds, I don’t think external validations ever really ‘validate’ the score in the sense we want clinically.
Other rules have set a clear target, but made that target 0%, which can never be proven, and will almost surely cause harm through false positives.
Trading sensitivity for specificity (decision rules are just another DDimer)
In medicine, we constantly struggle with the balance between sensitivity and specificity. (Whether we should even use these numbers is a different topic.) When we push for higher sensitivity, that essentially always comes at the cost of a lower specificity, and vice versa.
For the most part, clinical decision rules have erred on the side of high sensitivity at the cost of specificity. Some aim at the impossible 100% sensitivity, but almost all aim to be as close to 100% sensitive as possible, which is understandable, as physicians are unlikely to use a rule that tends to miss important diagnoses. Unfortunately, that means most rules end up with very poor specificities.
What is another test with a high sensitivity and a poor specificity? Correct. Clinical decision rules are the lab-free version of a D-dimer. Highly sensitive, poorly specific, and used to help us decide whether to order a CT scan. That is an equally good description of the D-dimer and at least a dozen clinical decision rules. Have you ever, in your entire clinical career, wished for another version of the D-dimer?
In fact, clinical decision rules might be significantly worse than the D-dimer. We are cautious about ordering D-dimers because we know they suck, but we are completely indiscriminate in our application of decision rules. Ordering a blood test is more difficult than pulling up MDCalc, so decision rules are more like D-dimers that we just send on every single patient. Does that sound like a good idea to you?
I think the D-dimer analogy is really important. It tells us we need to be very careful about our use of decision rules. It reminds us that these rules, if used incorrectly, can cause a lot of harm. However, it also reminds us not to throw the baby out with the bathwater. The D-dimer – when used smartly – is a tremendously valuable tool. I am not saying that decision rules can’t possibly help. I am just saying that most aren’t helping the way they are currently being used in medicine.
Clinical decision rules often ignore the foundations of evidence based medicine
This will be controversial, but I think it is essential. Evidence based medicine is about more than just literature, which is where most decision rules get stuck. True evidence based medicine must incorporate physician judgement and patient values. The way that most decision rules are created subverts this essential aspect of EBM.
Proponents always say that these rules should guide clinical decisions, not mandate decisions. (Unfortunately, lawyers and our colleges generally don’t think this way). However, despite these statements, the rules are often formulated in such a way that limits our ability to make nuanced decisions.
Rules are often directive. The output is often a clinical action. You either pass NEXUS and are told no imagining is necessary, or you fail and are told to image. You can pass PERC or fail, but what if it is a borderline decision? What if the only reason the patient fails is because they are 51 years old? The risk must be different than if they were 70 with unilateral leg swelling, hemoptysis, and a prior PE, but according to the rule, those two patients get the exact same result. The rule doesn’t support clinical judgement. The rule doesn’t allow for patient values. It is a binary yes or no.
Used alone, decision rules can actually decrease patient satisfaction. (Finnerty 2015; Kline 2014) Shared decision making improves patient satisfaction, but it isn’t clear how most rules are supposed to be implemented with shared decision making, considering the outputs of the rules are often opaque. (The PECARN head instrument would be a good exception, as it provides both clinical suggestions and numerical risks that can be used to shape a shared decision making conversation.) How do I use the binary outcomes of PERC to support shared decision making? How does the Ottawa ankle rule support a shared decision?
Important subjective decisions are often hidden within rules. For example, in the creation of the Ottawa ankle rule, the researchers decided on a cut-point with 100% sensitivity, because they assumed that clinicians wouldn’t want to use a rule with imperfect sensitivity. But is that really true? Would it be the end of the world if I occasionally missed a non-surgical ankle fracture? Does it matter if I have to transfer the patient a long distance, or hold them overnight for the x-ray? There was apparently an alternate cut point with 96% sensitivity which performed much better in its ability to decrease x-ray usage because of a much better specificity. (Laupacis 1997; Reilly 2006) The decision of which rule, with which test characteristics, to publish is substantial, but is made opaquely by a small handful of researchers. Shouldn’t decisions about risk tolerance be made by physicians and (more importantly) their patients?
Clinical decision rules are often sold as ‘decision aids’. We talk about them as if they should guide, not dictate care, but that is not how they are implemented. With the rare exception, it is not even clear how they could be used this way. Key clinical decisions are hidden within the development process, and the outputs of these rules are binary and not conducive to shared decision making. Thus, by essentially excluding clinical judgement and patient values, most decision rules ignore the foundations of evidence based medicine.
Clinical decision rules often inappropriately shape practice
This section really only has anecdotal evidence, but the anecdotal evidence is strong.
How often have you watched a resident perform an ankle exam and they only palpate the areas described by the Ottawa ankle rules? Listen to any Arun Sayal lecture, and you will hear about countless orthopaedic misses that result from misunderstandings about decision rules. If you don’t palpate the proximal leg, you can’t possibly find the Maisonneuve fracture, but that step is often skipped because it isn’t part of the rule. It isn’t the rule’s (or the researchers’) fault, but it is what happens when the rules are released into the wild.
The same is true of almost every topic. Clinicians who rely on decision rules for acute coronary syndrome are more likely to overlook atypical risk factors not included in those rules, like chronic cocaine use or systemic lupus. Consultants will tell me to discharge a patient based on a low risk PESI score or CURB 65 score, when I know that is clinically inappropriate for other reasons. When you ask a student if they think the patient has a PE, they will often respond with a score rather than an answer. The rules aren’t meant to be reductive, but because the results are usually presented as binary, they have a tendency to crowd out other factors that should influence clinical judgement.
Even when rules might be good, we misapply them
Although this is not the rule’s fault, it is still a well known consequence of applying decision rules, and so must be considered whenever we suggest the use of clinical decision rules.
We use them on the wrong patients
Inclusion and exclusion criteria of rules are incredibly important, and frequently ignored.
The CENTOR score for paediatrics is only supposed to be used in patients with a sore throat for less than 3 days, but this criteria is frequently ignored, undermining the scientific footing of the rule. (Carmelli 2018)
The Canadian CT head rule only applies to patients with blunt trauma and a witnessed loss of consciousness, definite amnesia, or witnessed disorientation. Those were the inclusion criteria of the study. (Stiell 2001) In the mind of the researchers, no one would be crazy enough to even consider a CT scan in a patient who hadn’t lost consciousness, had amnesia, or had clear disorientation. No one in 2001 would consider scanning such trivial injuries. Sadly, these researchers were not able to predict the sad decline of clinical medicine. In 2023, we have forgotten their inclusion criteria altogether. In fact, we would probably purposefully ignore their criteria, refusing to apply the decision rule to a patient with significant amnesia or disorientation, because we think those patients are ‘way too high risk for a decision rule’. Instead, we apply the rule to every single patient who falls, whether they hit their head or not, which means that every patient over the age of 65 gets a CT scan of their head, because they failed a rule that never even applied to them.
Obviously, it is not the researchers’ fault that clinicians mis-use their rules. (At least, not entirely. Researchers certainly play a large role in pushing for their rules to be used. In my mind, after the implementation study of the Canadian CT head rule failed to show benefit, there probably was some responsibility on the part of the researchers to de-promote the use of the rule.) However, whatever their intentions, it is essential that we address the real world impact of clinical decision rules. No rule will ever be used perfectly. We must account for imperfect use when studying the rule. We must discuss the potential harms of these rules. For these reasons, we really should not be implementing rules until they have been proven to provide patient benefit in real world implementation studies.
A bigger concern may be the more subtle differences between populations. (This is why we often want to see multiple external validations, and why so many rules fail on these external validations.) I imagine that if we reflected on our own practices, we might find significant deviations from the evidence produced to support these rules. For example, the NEXUS c-spine rule was only able to avoid imaging in 13% of the validation cohort. (Hoffman 2000) In my practice, more than 90% of patients pass NEXUS. Admittedly, I don’t work at a trauma centre, but that discrepancy is striking. I am clearly applying the rule in a very different population than originally intended, and I had no idea until researching this article. The problem is that the inclusion criteria for the original paper were “patients with blunt trauma who underwent radiography of the cervical spine”, but I am part of a generation that was trained after NEXUS was published, and so it is part of my decision making for who should get imaging. I am therefore left with the circular and completely illogical inclusion criteria that I should apply NEXUS to anyone who fails NEXUS. I will never be able to capture the clinical gestalt that went into this decision prior to 2000, and so the published data may not apply to my practice. I don’t know how NEXUS would perform if studied again in 2023, but I think it is a fair bet that the results would be dramatically different.
We mistake one-way and two-way rules
There are many rules designed to be used as ‘one way’ rules. In general, they are used to exclude the need for imaging, but failure of the rule should not indicate the need for imaging. (Finnerty 2015)
PERC is a one way rule that should be used to help avoid testing. It should not be used to start testing in a low risk patient. Obviously, not every 50 year old with chest pain needs a PE work-up, but many clinicians feel compelled to order tests when patients fail the rule. (Carmelli 2018)
Any uni-directional rule should be approached with extreme caution. They may be perfectly fine in theory, but we know from experience that they are almost never used unidirectionally. We know that if the rule is implemented, it will be used, at least a proportion of the time, as a bi-directional rule. In other words, we know these rules will be mis-used. Therefore, unlike some rules that provide various levels of risk, one-way rules should never be used based on validation studies alone. The validation numbers are almost irrelevant, as we know the test will be mis-used in clinical practice. One way rules should never be used until there are impact studies demonstrating benefit to patients, because there is a very high risk they will actually cause harm. (See the discussion about the Canadian CT head rule above.)
The researchers may not intend for their rules to be mis-used, but they should acknowledge that they will be, and temper their recommendations until we see proof of true patient oriented benefit.
We invent “Franken-rules”
As a consequence of the sheer number of rules available, we sometimes mix and match them in ways never intended and completely unsupported by science. This can be accidental, when people confuse the items on the PERC and Wells’ scores. However, somewhat unfathomably, this is also often done on purpose. I have seen many educators teach a combination of the Canadian C-Spine rule and NEXUS. Usually this takes the form of passing NEXUS, and then adding the neck range of motion from the Canadian rule. I have even seen this taught at major conferences, despite clearly being bad medicine. Considering the close to 100% sensitivity of each rule on its own, this combination can only be worse than either individual rule, reducing specificity, increasing imaging, and harming patients.
Bottom line
We clearly mis-apply decision rules and it causes harm. Rules designed to decrease testing are actually increasing testing. How often is a DDimer sent on a 51 year old only because they failed PERC? How often is a CT head ordered on a 66 year only only because they failed the Canadian CT head rule? The problems are not necessarily inherent to the rules, but the cat is out of the bag, and many of our rules are making clinical decision making worse rather than better.
Can we use rules with incomplete evidence?
Realistically, almost none of our rules have implementation data proving benefit. What are we supposed to do with all these rules which only have validation studies?
We clearly shouldn’t be implementing rules without evidence of benefit. Our experience with the Canadian CT head rule really emphasises this. Even rules that look great on paper can backfire, increasing testing, and causing harm.
Most rules are designed to have very high sensitivities at the expense of specificity. In other words, clinical decision rules are the equivalent of the D-dimer. Do you really need more D-dimers in your life?
However, even though most rules are not ready for clinical application, the research that underpins them is fantastic and shouldn’t be ignored. We should use these datasets to fine tune our clinical judgement; to learn which clinical features are the most salient. We should use these rules to teach our students. When rules provide us with clear numbers, we can use those numbers to help guide shared decision making conversations. We just shouldn’t broadly implement them until we see evidence of benefit, because there is also a strong possibility that they actually cause harm.
The distinction between implementing rules and learning from rules is complex but critical. If I am assessing a child with a head injury, and they fall into the lowest risk PECARN category, do I ignore the PECARN rule? Of course not. PECARN has been externally validated, so I trust the numbers and believe the patient is low risk.
However, there are no randomised, controlled implementation studies looking at the PECARN rule. For all I know, if PECARN was widely taught and recommended in my department, it would cause harm. It could easily increase imaging. (In fact, looking at the numbers in the PECARN before and after studies, I think it almost certainly would increase imaging in my department.) Therefore, although I will use the result of the PECARN score myself in an individual patient, I do not think it should be widely implemented or recommended until we can demonstrate it actually helps patients.
This distinction is incredibly fuzzy, but important to consider. A rule that allows us to safely use an elevated D-dimer threshold is great if we apply that rule to the same patients we are currently working up. If we allow that rule to change our practice – ordering more D-dimers because we are less afraid of borderline results – the same rule could be very harmful. We should not implement it without evidence of benefit, but that doesn’t mean I wouldn’t consider the rule if it were well validated.
Put another way, I will not use rules with incomplete evidence to help me make decisions, but I will allow them to talk me out of a test I have already decided to order. If I am unsure whether imagining is needed, I will not turn to the PECARN rule to make that decision, because without implementation studies, we have no idea if using the rule this way helps our patients. However, once I am convinced that a patient does need imaging, I will look at the PECARN rule, and will allow it to talk me out of imaging, because despite the lack of implementation research, it has been validated, so I can trust the high sensitivity to convince me imagining is unnecessary despite my initial instincts.
Yes, I know this distinction is going to break a lot of brains and cause a lot of arguments. If you have a better way of tackling this issue, please have a go in the comments.
Arguments for rules
A lot of people who are a lot smarter than me strongly support decision rules, and I agree that there are many theoretical reasons that decision rules might be helpful. I just don’t think that decision rules, as they are currently being used, are improving the practice of medicine. (I think this is a really important topic, so I am hoping that decision rule proponents will continue the discussion in the comments section.)
There is massive variability in modern clinical practice, and one of the main arguments for clinical decision rules is that they can help us standardize practice. Ideally, patients should receive the same high quality care whatever physician they are randomly assigned to see. Indeed, even a single physician can vary dramatically across a single shift, depending on hunger, fatigue, distractions, and a million other factors. Decision rules have the potential to standardize practice, and that is powerful, but we have to be careful if we are standarizing to mediocrity.
If decision rules don’t change practice as a whole in implementation studies, it is hard to argue that standardization is improving patient care. You might be improving the practice of the lowest quartile of physicians, but if there is no benefit overall, that means you are also diminishing the practice of our best doctors. However, this issue deserves a lot more nuanced attention than it has received to date. Perhaps decision rules don’t improve my practice overall, but might improve my decision making at 4:00 am, or at the end of a 12 hour shift. Standardization is an excellent goal, but it still needs to be accompanied by evidence of benefit for patients. For now, if you consider yourself a sub-par physician, decision rules are for you. If you consider yourself an exemplary physician, do you really want your care standardized to the mean? In that context, I am very interested to see how many people choose to use these rules on shift tomorrow.
Another argument for the use of decision rules is that they can be valuable training tools. Although I agree that we should incorporate the wealth of information these studies provide us, that doesn’t mean that they should be taught as rules. As rules, they can actually derail education, because instead of understanding each individual component as having a likelihood ratio of its own, we only teach the rule as a composite, and the decision appears to be black and white. If we use rules with poor specificity to train a new generation of doctors, we will be left with a generation of doctors with poor specificity. If a rule is not better than clinical judgement, it doesn’t make sense to use it as the basis of teaching clinical judgement. We should embrace the incredible datasets these rules provide, and use them to teach important diagnostic variables, but I don’t think we should be teaching them as rules until there is evidence that they function beneficially as rules.
Another common argument in favour of rules is that they could be legally protective. Although I sympathize with physicians who have to work in difficult legal environments, I am not sure this is a great argument. Rules that haven’t been proven to help can increase testing, so we can end up doing a lot of harm. No physician wants to harm their patients just to protect themselves. More importantly, these rules are only superficially objective. You might calculate a HEART score of 3, but the plaintiff’s expert will swear you should have made it 4. The false objectivity these rules create may actually place us at higher risk. At very least, it adds significant pressure that wouldn’t be present if we just universally rejected rules that weren’t adequately proven. I don’t think decision rules are the answer to legal issues (although I am very thankful to work in a setting where this is a minor issue.) Shared decision making is a much better approach, being both legally protective and providing better care for our patients.
Intent doesn’t matter
Although I clearly think that clinical decision rules have caused a lot of problems in modern medicine, I have nothing but respect for the researchers. The studies that underlie these rules are among the best we have in emergency medicine. Theoretically, decision rules could be great, if they were fully studied (all the way through implementation showing they actually improve care). However, we must acknowledge how they are being used in the real world.
- No one who creates decision tools intends for them to be used without being fully studied, but almost none of them are studied all the way through implementation.
- No one who creates decision tools intends for them to be used against you in malpractice suits, but that is how they are used in the real world.
- No one who creates decision tools intends for them to replace clinical judgement, but that’s how they are used in the real world.
- No one who creates decision tools intends for them to be applied incorrectly, but that is what happens in the real world.
- No one who creates decision tools intends for their decision rule to increase testing, but that happens in the real world.
- No one who creates decision tools intends for them to cause harm, but that seems to be happening in the real world.
- No one who creates decision tools intends to make a decision rule that is no better than clinical judgement, but that is what happens in the real world.
Intent doesn’t matter. We have to take the real world application into account when judging the value of clinical decision rules.
Summary
Overall, the way they are currently used, I honestly think that medicine would be better off without any decision rules at all. But we don’t need to be that extreme. We shouldn’t throw the baby out with the bathwater.
Decision rules are like any diagnostic test. Decision rules are like a D-dimer in sheep’s clothing. The D-dimer is a horrible test when used indiscriminately, but can be very helpful when used thoughtfully. We have to think about our decision rules like D-dimers. We should use them, but we need to use them very carefully.
We need to be much more cautious in our application of decision rules. We need rules that are proven to provide patient oriented benefit. We need rules that are better than clinical judgement.
Ideally, rules should not be adopted until we see impact analyses in multiple settings proving patient oriented benefit, or at least cost or time savings. Rules without impact analyses should not be used as rules. If they are broadly validated, it is reasonable to consider risk predictions of the rules in clinical decision making, but without impact analyses these rules should not be used clinically, recommended in guidelines, nor used in courts or by governing bodies.
Decision rules are ruining medicine and we need to act now to solve this problem.
Other FOAMed
EM Ottawa Epi Lessons Part 4 – DECISION RULE ARTICLES
References
Al Omar MZ, Baldwin GA. Reappraisal of use of X-rays in childhood ankle and midfoot injuries. Emerg Radiol. 2002 Jul;9(2):88-92. doi: 10.1007/s10140-002-0207-x. Epub 2002 Mar 28. PMID: 15290584
Babl FE, Oakley E, Dalziel SR, et al. Accuracy of Clinician Practice Compared With Three Head Injury Decision Rules in Children: A Prospective Cohort Study. Annals of emergency medicine. 2018; 71(6):703-710. PMID: 29452747
Backus BE, Six AJ, Kelder JC, Mast TP, van den Akker F, Mast EG, Monnink SH, van Tooren RM, Doevendans PA. Chest pain in the emergency room: a multicenter validation of the HEART Score. Crit Pathw Cardiol. 2010 Sep;9(3):164-9. doi: 10.1097/HPC.0b013e3181ec36d8. PMID: 20802272
Backus BE, Six AJ, Kelder JC, Bosschaert MA, Mast EG, Mosterd A, Veldkamp RF, Wardeh AJ, Tio R, Braam R, Monnink SH, van Tooren R, Mast TP, van den Akker F, Cramer MJ, Poldervaart JM, Hoes AW, Doevendans PA. A prospective validation of the HEART score for chest pain patients at the emergency department. Int J Cardiol. 2013 Oct 3;168(3):2153-8. doi: 10.1016/j.ijcard.2013.01.255. Epub 2013 Mar 7. PMID: 23465250
Bressan S, Romanato S, Mion T, Zanconato S, Da Dalt L. Implementation of adapted PECARN decision rule for children with minor head injury in the pediatric emergency department. Acad Emerg Med. 2012 Jul;19(7):801-7. doi: 10.1111/j.1553-2712.2012.01384.x. Epub 2012 Jun 22. PMID: 22724450
Carmelli G, Grock A, Picart E, Mason J. The Nitty-Gritty of Clinical Decision Rules. Ann Emerg Med. 2018 Jun;71(6):711-713. doi: 10.1016/j.annemergmed.2018.04.004. PMID: 29776497
Cameron C, Naylor CD. No impact from active dissemination of the Ottawa Ankle Rules: further evidence of the need for local implementation of practice guidelines. CMAJ. 1999 Apr 20;160(8):1165-8. PMID: 10234347
Cosgriff TM, Kelly AM, Kerr D. External validation of the San Francisco Syncope Rule in the Australian context. CJEM. 2007 May;9(3):157-61. doi: 10.1017/s1481803500014986. PMID: 17488574
Glas AS, Pijnenburg BA, Lijmer JG, Bogaard K, de RM, Keeman JN, Butzelaar RM, Bossuyt PM. Comparison of diagnostic decision rules and structured data collection in assessment of acute ankle injury. CMAJ. 2002 Mar 19;166(6):727-33. Erratum in: CMAJ 2002 Apr 30;166(9):1135. PMID: 11944759
Green SM, Schriger DL. A Methodological Appraisal of the HEART Score and Its Variants. Ann Emerg Med. 2021 Aug;78(2):253-266. doi: 10.1016/j.annemergmed.2021.02.007. Epub 2021 Apr 29. PMID: 33933300
Finnerty NM, Rodriguez RM, Carpenter CR, Sun BC, Theyyunni N, Ohle R, Dodd KW, Schoenfeld EM, Elm KD, Kline JA, Holmes JF, Kuppermann N. Clinical Decision Rules for Diagnostic Imaging in the Emergency Department: A Research Agenda. Acad Emerg Med. 2015 Dec;22(12):1406-16. doi: 10.1111/acem.12828. Epub 2015 Nov 14. PMID: 26567885
Freund Y, Cachanado M, Aubry A, Orsini C, Raynal PA, Féral-Pierssens AL, Charpentier S, Dumas F, Baarir N, Truchot J, Desmettre T, Tazarourte K, Beaune S, Leleu A, Khellaf M, Wargon M, Bloom B, Rousseau A, Simon T, Riou B; PROPER Investigator Group. Effect of the Pulmonary Embolism Rule-Out Criteria on Subsequent Thromboembolic Events Among Low-Risk Emergency Department Patients: The PROPER Randomized Clinical Trial. JAMA. 2018 Feb 13;319(6):559-566. doi: 10.1001/jama.2017.21904. PMID: 29450523
Freund Y, Chauvin A, Jimenez S, Philippon AL, Curac S, Fémy F, Gorlicki J, Chouihed T, Goulet H, Montassier E, Dumont M, Lozano Polo L, Le Borgne P, Khellaf M, Bouzid D, Raynal PA, Abdessaied N, Laribi S, Guenezan J, Ganansia O, Bloom B, Miró O, Cachanado M, Simon T. Effect of a Diagnostic Strategy Using an Elevated and Age-Adjusted D-Dimer Threshold on Thromboembolic Events in Emergency Department Patients With Suspected Pulmonary Embolism: A Randomized Clinical Trial. JAMA. 2021 Dec 7;326(21):2141-2149. doi: 10.1001/jama.2021.20750. PMID: 34874418
Hoffman JR, Mower WR, Wolfson AB, Todd KH, Zucker MI. Validity of a set of clinical criteria to rule out injury to the cervical spine in patients with blunt trauma. National Emergency X-Radiography Utilization Study Group. N Engl J Med. 2000 Jul 13;343(2):94-9. doi: 10.1056/NEJM200007133430203. Erratum in: N Engl J Med 2001 Feb 8;344(6):464. PMID: 10891516
Holmes JF, Lillis K, Monroe D, Borgialli D, Kerrey BT, Mahajan P, Adelgais K, Ellison AM, Yen K, Atabaki S, Menaker J, Bonsu B, Quayle KS, Garcia M, Rogers A, Blumberg S, Lee L, Tunik M, Kooistra J, Kwok M, Cook LJ, Dean JM, Sokolove PE, Wisner DH, Ehrlich P, Cooper A, Dayan PS, Wootton-Gorges S, Kuppermann N; Pediatric Emergency Care Applied Research Network (PECARN). Identifying children at very low risk of clinically important blunt abdominal injuries. Ann Emerg Med. 2013 Aug;62(2):107-116.e2. doi: 10.1016/j.annemergmed.2012.11.009. Epub 2013 Feb 1. PMID: 23375510
Kabrhel C, Van Hylckama Vlieg A, Muzikanski A, Singer A, Fermann GJ, Francis S, Limkakeng A, Chang AM, Giordano N, Parry B. Multicenter Evaluation of the YEARS Criteria in Emergency Department Patients Evaluated for Pulmonary Embolism. Acad Emerg Med. 2018 Sep;25(9):987-994. doi: 10.1111/acem.13417. PMID: 29603819
Kline JA, Mitchell AM, Kabrhel C, Richman PB, Courtney DM. Clinical criteria to prevent unnecessary diagnostic testing in emergency department patients with suspected pulmonary embolism. J Thromb Haemost. 2004 Aug;2(8):1247-55. doi: 10.1111/j.1538-7836.2004.00790.x. PMID: 15304025
Kline JA, Jones AE, Shapiro NI, Hernandez J, Hogg MM, Troyer J, Nelson RD. Multicenter, randomized trial of quantitative pretest probability to reduce unnecessary medical radiation exposure in emergency department patients with chest pain and dyspnea. Circ Cardiovasc Imaging. 2014 Jan;7(1):66-73. doi: 10.1161/CIRCIMAGING.113.001080. Epub 2013 Nov 25. PMID: 24275953
Laupacis A, Sekar N, Stiell IG. Clinical prediction rules. A review and suggested modifications of methodological standards. JAMA. 1997 Feb 12;277(6):488-94. PMID: 9020274
Matteucci MJ, Moszyk D, Migliore SA. Agreement between resident and faculty emergency physicians in the application of NEXUS criteria for suspected cervical spine injuries. J Emerg Med. 2015 Apr;48(4):445-9. doi: 10.1016/j.jemermed.2014.11.006. Epub 2015 Jan 22. PMID: 25618832
Meltzer AC, Baumann BM, Chen EH, Shofer FS, Mills AM. Poor sensitivity of a modified Alvarado score in adults with suspected appendicitis. Ann Emerg Med. 2013 Aug;62(2):126-31. doi: 10.1016/j.annemergmed.2013.01.021. Epub 2013 Apr 24. PMID: 23623557
Mintegi S, Bressan S, Gomez B, Da Dalt L, Blázquez D, Olaciregui I, de la Torre M, Palacios M, Berlese P, Benito J. Accuracy of a sequential approach to identify young febrile infants at low risk for invasive bacterial infection. Emerg Med J. 2014 Oct;31(e1):e19-24. doi: 10.1136/emermed-2013-202449. Epub 2013 Jul 14. PMID: 23851127
Nigrovic LE, Stack AM, Mannix RC, Lyons TW, Samnaliev M, Bachur RG, Proctor MR. Quality Improvement Effort to Reduce Cranial CTs for Children With Minor Blunt Head Trauma. Pediatrics. 2015 Jul;136(1):e227-33. doi: 10.1542/peds.2014-3588. PMID: 26101363
Quinn JV, Stiell IG, McDermott DA, Sellers KL, Kohn MA, Wells GA. Derivation of the San Francisco Syncope Rule to predict patients with short-term serious outcomes. Ann Emerg Med. 2004 Feb;43(2):224-32. doi: 10.1016/s0196-0644(03)00823-0. PMID: 14747812
Quinn J, McDermott D, Stiell I, Kohn M, Wells G. Prospective validation of the San Francisco Syncope Rule to predict patients with serious outcomes. Ann Emerg Med. 2006 May;47(5):448-54. doi: 10.1016/j.annemergmed.2005.11.019. Epub 2006 Jan 18. PMID: 16631985
Ranson JH, Rifkind KM, Roses DF, Fink SD, Eng K, Spencer FC. Prognostic signs and the role of operative management in acute pancreatitis. Surg Gynecol Obstet. 1974 Jul;139(1):69-81. PMID: 4834279
Reilly BM, Evans AT. Translating clinical research into clinical practice: impact of using prediction rules to make decisions. Ann Intern Med. 2006 Feb 7;144(3):201-9. doi: 10.7326/0003-4819-144-3-200602070-00009. PMID: 16461965
Righini M, Van Es J, Den Exter PL, Roy PM, Verschuren F, Ghuysen A, Rutschmann OT, Sanchez O, Jaffrelot M, Trinh-Duc A, Le Gall C, Moustafa F, Principe A, Van Houten AA, Ten Wolde M, Douma RA, Hazelaar G, Erkens PM, Van Kralingen KW, Grootenboers MJ, Durian MF, Cheung YW, Meyer G, Bounameaux H, Huisman MV, Kamphuisen PW, Le Gal G. Age-adjusted D-dimer cutoff levels to rule out pulmonary embolism: the ADJUST-PE study. JAMA. 2014 Mar 19;311(11):1117-24. doi: 10.1001/jama.2014.2135. Erratum in: JAMA. 2014 Apr 23-30;311(16):1694. PMID: 24643601
Sanders S, Doust J, Glasziou P. A systematic review of studies comparing diagnostic clinical prediction rules with clinical judgement. PLoS One. 2015 Jun 3;10(6):e0128233. doi: 10.1371/journal.pone.0128233. PMID: 26039538
Schriger DL, Elder JW, Cooper RJ. Structured Clinical Decision Aids Are Seldom Compared With Subjective Physician Judgment, and Are Seldom Superior. Ann Emerg Med. 2017 Sep;70(3):338-344.e3. doi: 10.1016/j.annemergmed.2016.12.004. Epub 2017 Feb 24. PMID: 28238497
Seymour CW, Liu VX, Iwashyna TJ, Brunkhorst FM, Rea TD, Scherag A, Rubenfeld G, Kahn JM, Shankar-Hari M, Singer M, Deutschman CS, Escobar GJ, Angus DC. Assessment of Clinical Criteria for Sepsis: For the Third International Consensus Definitions for Sepsis and Septic Shock (Sepsis-3). JAMA. 2016 Feb 23;315(8):762-74. doi: 10.1001/jama.2016.0288. Erratum in: JAMA. 2016 May 24-31;315(20):2237. PMID: 26903335
Singh-Ranger G, Marathias A. Comparison of current local practice and the Ottawa Ankle Rules to determine the need for radiography in acute ankle injury. Accid Emerg Nurs. 1999 Oct;7(4):201-6. doi: 10.1016/s0965-2302(99)80051-4. PMID: 10808759
Six AJ, Backus BE, Kelder JC. Chest pain in the emergency room: value of the HEART score. Neth Heart J. 2008 Jun;16(6):191-6. doi: 10.1007/BF03086144. PMID: 18665203
Stiell IG, Greenberg GH, McKnight RD, Nair RC, McDowell I, Reardon M, Stewart JP, Maloney J. Decision rules for the use of radiography in acute ankle injuries. Refinement and prospective validation. JAMA. 1993 Mar 3;269(9):1127-32. doi: 10.1001/jama.269.9.1127. PMID: 8433468
Stiell IG, McKnight RD, Greenberg GH, McDowell I, Nair RC, Wells GA, Johns C, Worthington JR. Implementation of the Ottawa ankle rules. JAMA. 1994 Mar 16;271(11):827-32. PMID: 8114236
Stiell I, Wells G, Laupacis A, Brison R, Verbeek R, Vandemheen K, Naylor CD. Multicentre trial to introduce the Ottawa ankle rules for use of radiography in acute ankle injuries. Multicentre Ankle Rule Study Group. BMJ. 1995 Sep 2;311(7005):594-7. doi: 10.1136/bmj.311.7005.594. PMID: 7663253
Stiell IG, Wells GA, Hoag RH, Sivilotti ML, Cacciotti TF, Verbeek PR, Greenway KT, McDowell I, Cwinn AA, Greenberg GH, Nichol G, Michael JA. Implementation of the Ottawa Knee Rule for the use of radiography in acute knee injuries. JAMA. 1997 Dec 17;278(23):2075-9. PMID: 9403421
Stiell IG, Wells GA, Vandemheen K, Clement C, Lesiuk H, Laupacis A, McKnight RD, Verbeek R, Brison R, Cass D, Eisenhauer ME, Greenberg G, Worthington J. The Canadian CT Head Rule for patients with minor head injury. Lancet. 2001 May 5;357(9266):1391-6. doi: 10.1016/s0140-6736(00)04561-x. PMID: 11356436
Stiell IG, Clement CM, Grimshaw J, Brison RJ, Rowe BH, Schull MJ, Lee JS, Brehaut J, McKnight RD, Eisenhauer MA, Dreyer J, Letovsky E, Rutledge T, MacPhail I, Ross S, Shah A, Perry JJ, Holroyd BR, Ip U, Lesiuk H, Wells GA. Implementation of the Canadian C-Spine Rule: prospective 12 centre cluster randomised trial. BMJ. 2009 Oct 29;339:b4146. doi: 10.1136/bmj.b4146. PMID: 19875425
Stiell IG, Clement CM, Grimshaw JM, Brison RJ, Rowe BH, Lee JS, Shah A, Brehaut J, Holroyd BR, Schull MJ, McKnight RD, Eisenhauer MA, Dreyer J, Letovsky E, Rutledge T, Macphail I, Ross S, Perry JJ, Ip U, Lesiuk H, Bennett C, Wells GA. A prospective cluster-randomized trial to implement the Canadian CT Head Rule in emergency departments. CMAJ. 2010 Oct 5;182(14):1527-32. doi: 10.1503/cmaj.091974. Epub 2010 Aug 23. PMID: 20732978
Sun BC, Mangione CM, Merchant G, Weiss T, Shlamovitz GZ, Zargaraff G, Shiraga S, Hoffman JR, Mower WR. External validation of the San Francisco Syncope Rule. Ann Emerg Med. 2007 Apr;49(4):420-7, 427.e1-4. doi: 10.1016/j.annemergmed.2006.11.012. Epub 2007 Jan 8. PMID: 17210201
Thiruganasambandamoorthy V, Hess EP, Alreesi A, Perry JJ, Wells GA, Stiell IG. External validation of the San Francisco Syncope Rule in the Canadian setting. Ann Emerg Med. 2010 May;55(5):464-72. doi: 10.1016/j.annemergmed.2009.10.001. Epub 2009 Nov 27. PMID: 19944489
Vertesi L. Risk Assessment Stratification Protocol (RASP) to help patients decide on the use of postexposure prophylaxis for HIV exposure. CJEM. 2003 Jan;5(1):46-8. doi: 10.1017/s1481803500008113. PMID: 17659153
Wang RC, Rodriguez RM, Moghadassi M, Noble V, Bailitz J, Mallin M, Corbo J, Kang TL, Chu P, Shiboski S, Smith-Bindman R. External Validation of the STONE Score, a Clinical Prediction Rule for Ureteral Stone: An Observational Multi-institutional Study. Ann Emerg Med. 2016 Apr;67(4):423-432.e2. doi: 10.1016/j.annemergmed.2015.08.019. Epub 2015 Oct 3. PMID: 26440490
Wells PS, Anderson DR, Rodger M, Forgie M, Kearon C, Dreyer J, Kovacs G, Mitchell M, Lewandowski B, Kovacs MJ. Evaluation of D-dimer in the diagnosis of suspected deep-vein thrombosis. N Engl J Med. 2003 Sep 25;349(13):1227-35. doi: 10.1056/NEJMoa023153. PMID: 14507948




16 thoughts on “Clinical decision rules are ruining medicine”
Thank you for this great post , Justin . I am currently writing a book chapter on decision making with many of the same arguments against CDRs as you
Beside all the problems with research and validation (which are important in their own right), I think the core idea of simplistic standardisation in complex situations (such as assessing the undifferentiated ED patient) is problematic , and Cognitive Psychologist , Gary Klein has explained that such standardisation leads to “erosion of expertise” when we attempt to procesuralize our decisions (streetlights and shadows).
As you also mention , the knowledge once held by us as a community erodes (or is at least changed often for the worse) as a CDR is implemented – Weingart argues in this OODA loop and breadbaking SMACC talk on the use of guidelines may be good in a novice but the novice must jettison the guidelines when becoming more experienced or never reach there.
Also, in all of the standardisation discussion , I think we are lagging the concept of “appropriate variability” (standardisation is good if a problem is “simple” but when complex , too many factors need to be taken into account for it to be put in an algorithm – the place for algorithms is further down the diagnostic pathway when the “problem” has been simplified through judgement of an expert). When I know my hip is broken , I need someone in a fairly standard and reliable fashion to fix it (not saying there are not complex elements to this as well, but it’s a defined area, further downstream of the complex process of diagnostics) – when I come in with upper abdominal pain I want someone to be able to asses that it may have to do with the heart or maybe something psychosocial so that I don’t have to go through a cascade of care . Gary Klein writes of this obsession in standardisation of processes (same book): “procedures help when you need people to reliably follow the same steps. However , that’s different from needing reliable outcomes. A blacksmith must bring the hammer down at the same point stroke after stroke , yet we do not care if the arc of the hammer is the same each time”.
We should probably invest the money from much of the CDR research in deliberate practise and communication / bedside skills by expert supervisors (or shadow boxing), so that we can become experts (and maybe some money to expectation management of the population about the absurdity of 0% risk – this is probably the core of the problem. Lack of trust and unrealistic / skewed expectations from all of us on healthcare)
As always I think too little emphasis is being put on “how to acquire the information to put into our CDRs” (or any other test for that matter). Now that Pandora’s CDR box has been opened , I think the least we can do is to apply them in the right population and not widely / with creep
I’ll end with my favourite Klein quote about this topic
“ The notion that we can apply a rule—“If this condition arises, apply that treatment”—ignores the ability to judge whether the condition has arisen. Much, if not most, of the challenge is in understanding what is anomalous and the nature of the underlying problems” (Klein and Klein et al, Can We Trust Best Practices? Six Cognitive Challenges of Evidence-Based Approaches)
Sorry for the long write up. Thank you again for this blog and your work !
Thanks for the amazing comment. Can’t wait to read your book chapter.
I haven’t read this book by Klein, but it sounds very interesting.
Of everything, I think the biggest come from you you call expectation management in the general population, but I might refer to more as basic health literacy. I think the best investment in medicine really might be a elementary / highschool health curriculum designed by evidence based physicians. Although, maybe basic critical thinking skills are even more important. Can I just redesign most education curriculums?
This particular chapter sadly will be in danish , but I’ve begun to put out the same content in the English-spoken videos (i.e https://m.youtube.com/watch?v=vYxe1Ye2UA4&t=4792s) as time allows . My mentor in this area , Eric Dryver (EuSEM chair of education) has founded a course where we teach decision making and probabilistic thinking to emergency physicians (called Emergency Medicine Core Competences). Nothing in the chapter or the videos that you wouldn’t know , I’m sure .
Kleins books (and this one especially , I think) is very good at striking a more nuanced balance in the discussion of system 2 Vs 1 that, I believe, has been somewhat skewed towards system 2 / avoid errors (ie develop “fool proof” CDRs) possibly because of Kahnemanns popularity and his school of thought
Haha the “expectation management in the general population” is maybe more towards and Ivan Illich kind of “getting to terms with mortality”, empowerment and stoicism (memento morti kind of motto). I think Risk Litteracy , as you mention , probably is a very important factor as well, and is supported by giants in the decision making field such as Gerd Gigerenzer. I think you’re spot in with spending money on education of the population! However only patients but we as health care providers need to be better informed (and that triggles all the way through from research to guidelines to the bedside). So I can only thank you again that you are a very high quality part of this progress of making us all more risk literate! I’d trust you to redesign the curriculums before most others currently doing it!
Justin, great stuff. IMHO, much more attention needs to be given to the one way direction of most of these rules (no means no, but not no does not mean yes). A rule created to avoid testing does not mean testing is needed if the patient fails the rule. For example, a patient who stepped in a pot hole sustained a trimalleolar fracture. The patient got a head and neck CT because of the NEXUS c-spine rule: pain caused by a “distracting injury”. There are sadly 1000’s of examples like this. With CDRs, we have come to behave like obedient and thoughtless children.
Thank you Peter. I totally agree. In fact, I really wonder if we should be putting out one way rules at all. They make sense in theory, but I think it is pretty clear at this point that clinicians are incapable of using them correctly. Worse, we train generations of doctors on these rules, and they become ingrained as the new generation’s clinical judgement, rather than being recognized as tools to be used in a very select group of patients.
Justin, thoughtful post, but I believe context is important. In the U.S. where the evidence shows that we dramatically overuse advanced imaging (as evidenced by low and declining diagnostic yield and/or lack of change in disease outcome from increased imaging), well-validated CDRs likley perform differently than in the countries where most implementation studies have been conducted (Canada and Europe). For example, while the Canadian head CT rule validation in Canada increased use of CT…that does not mean it would not decrease use in the US. It is unfortunate that there is not more study of CDRs in practice in the U.S.
Thanks for the comment
I think we agree entirely. These rules almost certainly have different value in different settings. I am not sure rules will help even in higher use settings, because the primary problem with the rules is low specificity, and the biggest problem with high use settings like the United States is not decisions about a select group of high risk patients, but the extrapolation of those decisions to a much larger group of very low risk patients. If these rules are applied to lower risk populations, they can still increase testing even in high use areas. In fact, I think it is very likely that this specific rule has been a strong contributor to the massive increase in CT use over the last decade, even in an already high use setting like the United States.
Excellent topic and post. Thank you!
My question goes a little bit off topic but:
Why so many canadian rules and scores? Are you that obsessed with algorithms and checklists? Eheh just messing around 🙂
Cheers!
Thanks for the comment.
The group in Ottawa (Canada) has produced some incredible research. World class. We have a ton of rules just because there are a lot of researchers in that center interested in rules.
I don’t think the rules themselves are necessarily fantastic, but the research underlying them absolutely is. I just think we need to find a better way to implement this kind of research, as CDRs seem to have too many problems.