
There have been a few new thrombolytic RCTs since I published my review of the stroke literature, and it is probably about time that I got around to writing about them. On the one hand, I think it is exciting that we are moving past the flawed time-based selection of patients, and exploring other options for deciding who might benefit from thrombolytics. On the other hand, the trials are flawed and don’t really provide any answers, so there isn’t much to be excited about. Tomorrow I will review a group of trials that uses perfusion based imaging to select patients with salvageable brain tissue. In my mind, that is the most promising approach. This review looks at the WAKE-UP trial, which uses an MRI technique that can identify strokes that are less than 4.5 hours old, regardless of the timing of the symptoms.
The paper
The WAKE UP Trial: Thomalla G, Simonsen CZ, Boutitie F, et al. MRI-Guided Thrombolysis for Stroke with Unknown Time of Onset. The New England journal of medicine. 2018; 379(7):611-622. PMID: 29766770 [free full text] ClinicalTrials.gov: NCT01525290
The Methods
The WAKE UP trial is a multicentre, randomized, double-blind, placebo controlled trial looking at MRI guided thrombolysis in patients with an unknown time of onset of their stroke.
Patients
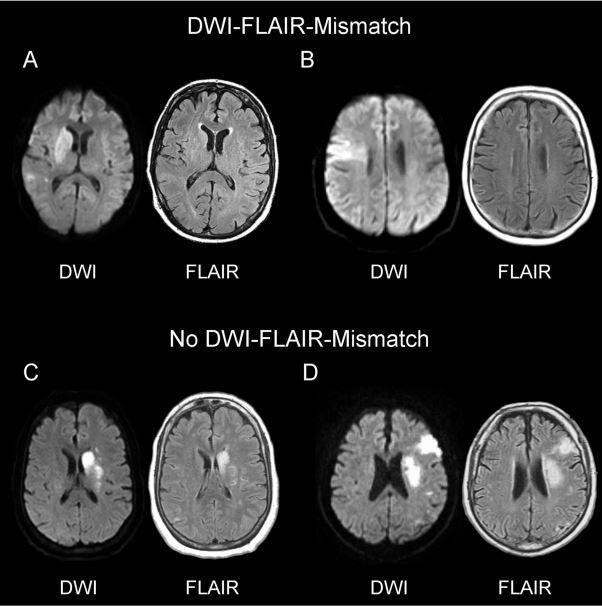
Eligible patients presented with clinical signs of acute stroke, were 18 to 80 years of age, and had been able to carry out usual activities in their daily life without support before the stroke. Patients either had stroke symptoms upon waking up, or were unable to report the time of onset, and it was at least 4.5 hours since they were last seen well. Patients could undergo randomization if in the judgment of the investigator MRI showed an acute ischemic lesion on diffusion-weighted imaging but no parenchymal hyperintensity with standard window settings on FLAIR. (This MRI pattern was chosen because it suggests that the stroke occurred approximately in the last 4.5 hours).
- Exclusions: Intracranial hemorrhage on MRI; lesions greater than ⅓ of the territory of the middle cerebral artery; planned thrombectomy; severe stroke (an NIHSS of greater than 25); contraindications to alteplase.
Intervention
Alteplase 0.9 mg/kg (10% given as a bolus and the remainder given over 1 hour).
Comparison
Placebo.
Outcome
The primary efficacy endpoint was a favorable clinical outcome, which was defined as a score of 0 or 1 on the modified Rankin scale 90 days after randomization. (Consistent with clinicaltrials.gov)
The primary safety endpoints were death and a composite outcome of death or dependence, which was defined as a score of 4 to 6 on the modified Rankin scale at 90 days.
The Results
They screened 1362 patients at 61 centres over almost 5 years to find 503 eligible patients. They were supposed to enroll 800 patients, but they stopped the trial early “on the basis of the anticipated cessation of funding from the European Union.” (This is a somewhat unusual reason for stopping a trial early.)
Of the 1362 patients screened, 455 were excluded for marked FLAIR lesion (meaning the stroke was older than 4.5 hours). Another 137 were excluded because the DWI was negative, indicating a stroke mimic. This makes it very clear that it would be unsafe to treat these wake up stroke patients without this advanced MRI screening.
The median NIHSS score on arrival was 6 (mild). 89% of patients had wake up strokes. The median time between symptom recognition and the administration of alteplase was 3.1 hours. The median time between when the patient was last seen well and the administration of alteplase was 10 hours.
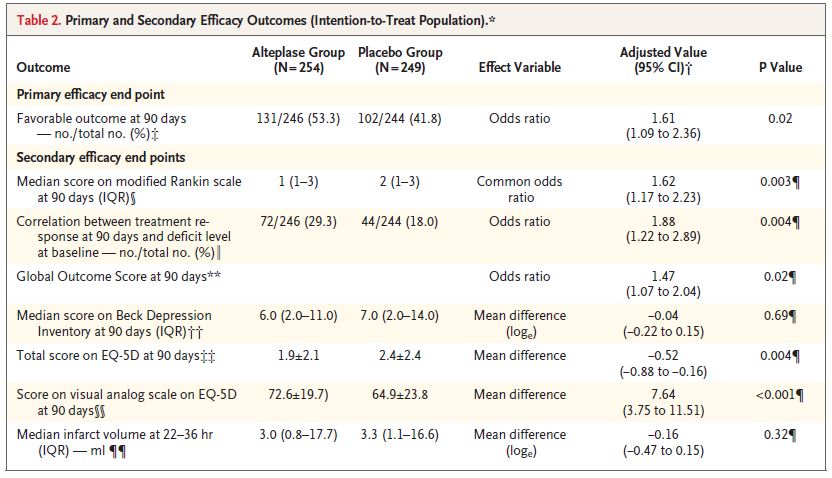
The primary outcome (a modified Rankin score of 0 or 1 at 90 days) occurred in 53% of the alteplase group and 42% of the placebo group (adjusted odds ratio, 1.61; 95% CI 1.09 to 2.36; P = 0.02).
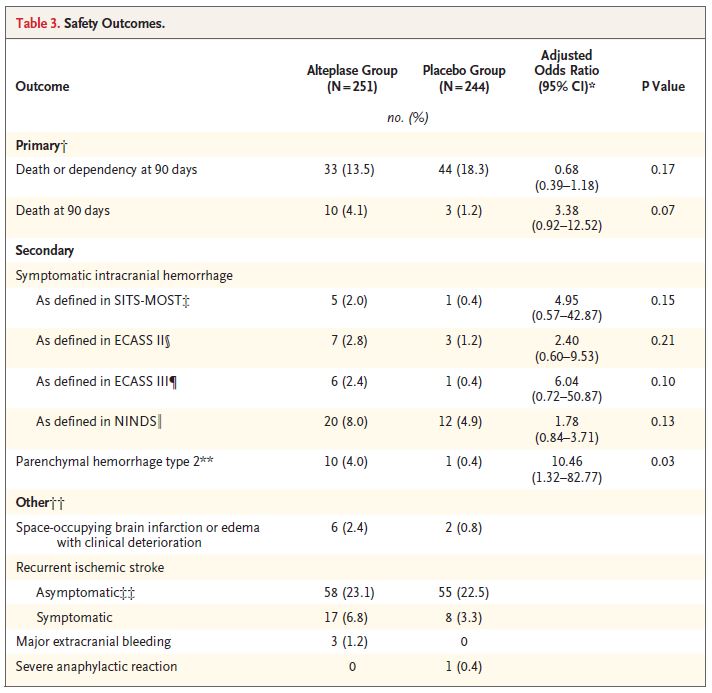
Mortality was 4.1% with alteplase and 1.2% with placebo (adjusted odds ratio, 3.38; 95% CI, 0.92 to 12.52; P = 0.07).
Intracranial hemorrhage was obviously higher with alteplase, and there were also more cases of recurrent stroke and cerebral edema.
My thoughts
I have long argued that we need to find a “STEMI equivalent” for stroke. Our current approach is too much like giving thrombolytics to every chest pain patient that walks through the door. It is bound to fail. Unfortunately, I don’t think we are any closer based on the results of this trial.
The results of the WAKE UP trial are probably not generalizable to most hospitals. Very few emergency departments have access to immediate MRI, and this trial required special software, and specially trained neuroradiologists to read the scans.
Although we could certainly make MRI and neuroradiologists more available, the tiny number of eligible patients might make that a poor investment of resources. They only managed to include 1.6 patients a year at each stroke center.
That either suggests significant selection bias, or that this is a very rare presentation which probably doesn’t warrant much attention. It also suggests that you absolutely need advanced imaging for wake-up strokes, as the majority of these patients either had a completed infarct or weren’t having a stroke at all, and were therefore excluded.
Although the trial wasn’t industry sponsored, the authors do have an impressively long list of conflicts of interest.
Increased mortality and stopping trials early
There are two common concerns when trials are stopped early. The first has to do with the law of large numbers and regression to the mean. A small number of events always has a greater chance of a more extreme results than a large number of events. This is intuitive in day to day life, but we sometimes lose track of the fact in medical trials. No one is surprised if you flip a coin and get 3 heads in a row. Someone might notice at 10 heads, but you aren’t calling the Guiness Book of World Records. However, by 1,000 heads in a row, you are pretty certain the coin is rigged.
With a small number of patients, trials are more likely to have extreme results. By chance alone, the results are more likely to deviate from the truth. As you add more patients, the law of large numbers kicks in and, in the absence of significant bias, the results regress back towards the true number. It is impossible to know how the numbers would have changed if the WAKE UP trial had been completed, but the confidence intervals come pretty close to 1, so any regression of the mean could have made this a negative trial.
The other problem with stopping trials early is that they become underpowered, potentially resulting in real differences being declaring “statistically insignificant”. There was a 2.9% increase in mortality in this trial, but because of the small number of patients, the confidence intervals are wide, and we are left with a barely “statistically insignificant” result, with a p value of 0.07. At the trial run to completion, it is very likely that this difference (if maintained) would have been “statistically significant”.
If a trial is stopped randomly, it seems like these forces might balance themselves out to some extent. However, trials are not stopped randomly. They are stopped for a reason, and that introduces significant bias. We stop positive trials early, when the results look unbelievably good, and prevent the likely regression to the mean. (For this reason, the benefit for endovascular therapy in stroke is likely over-estimated). On the other hand, we stop negative trials early for “futility”, not allowing enough time for the differences in adverse events to become statistically significant.
Because stopping trials early introduces significant bias, I think the most appropriate way to interpret these trials is by looking at the worst case scenario. Therefore, when assessing the benefit of trials stopped early, I look at the lowest end of the 95% confidence interval. On the other hand, when it comes to harm, I look for any differences that would be clinically important to me (like the 3% absolute increase in mortality seen here) and assume that it would be statistically significant if the trial had been completed.
The more opportunities you have to stop your trial early, the worse the bias becomes. (One of the worst forms of p-hacking is checking your statistics after each patient enrolled, and stopping the trial when you see a p value less than 0.05). Many trials have a few specific stop points for ethical reasons. Although these stop points can still distort the data for the reasons discussed above, the are a necessary component of trial design. However, the WAKE UP trial was stopped because of an anticipated loss of funding. They hadn’t lost funding yet, they just thought they might. How long had they known about this issue? Why did they stop after 503 patients? Why not 480 patients, or 510, or 504? The dramatic increase in researcher degrees of freedom provided by stopping a trial whenever you want introduces bias and makes the statistics far less reliable.
MRI as the STEMI equivalent
The time based approach to selecting patients for thrombolytics doesn’t seem to work. The Cochrane review concludes that the available data does not support a difference between the 0-3 hour and 3-6 hour groups. (Wardlaw 2009) This approach has always been based more on wishful thinking and the Texas sharp-shooter fallacy than it was on science.
Unfortunately, the imaging technique described here is really just another way of identifying patients who fall within a specific time window. If the WAKE UP results are true, it could lend some support to the time is brain philosophy. However, I think it is more likely that any benefit this approach provides arises from excluding stroke mimics and completed strokes, rather than the estimate that the mismatched strokes are less than 4.5 hours old. (Personally, I think the perfusion based imaging that we will discuss tomorrow makes more sense anyway). That being said, I am not sure we are seeing a real benefit, and there is also a hint of significant harm with the 3% increase in mortality.
This imaging based approach to stroke management needs to be explored further. We still desperately need a replication of NINDS, but I would probably modify it so that one group of patients was selected by time (less than 3 hours) and another group was selected based on imaging criteria, and both were compared to placebo.
Bottom line
In this trial, which has significant risk of bias, using MRI to select patients with an unknown time of stroke onset and giving them alteplase resulted in an 11% improvement in 90 day neurologic outcomes, but also probably increased mortality. Using advanced imaging to select stroke patients for thrombolytic therapy is promising, but should be considered unproven at this point. (Thrombolytic therapy in general is unproven, as we still await the necessary NINDS replication study.)
Other FOAMed
Thrombolytics for stroke: The evidence
REBEL EM – Extending the tPA Window to 4.5 – 9 Hours in Acute Ischemic Stroke (AIS)?
EM Lit of Note – Wake Up and Smell the tPA
Note of DWI and FLAIR in stroke
Neurologists and radiologists are likely to cringe at this simplified explanation, but DWI (diffusion weighted imaging) identifies local edema that indicates that the patient is truly having an ischemic stroke. These changes occur very rapidly (minutes). On the other hand, FLAIR (fluid attenuated inversion recovery) identifies vasogenic edema that only occurs hours later. Therefore, to ensure you are treating a stroke in the first few hours, you want DWI to be positive but FLAIR to be negative.
References
Bassler D. Stopping Randomized Trials Early for Benefit and Estimation of Treatment EffectsSystematic Review and Meta-regression Analysis JAMA. 2010; 303(12):1180-.
Lees KR, Bluhmki E, von Kummer R, et al. Time to treatment with intravenous alteplase and outcome in stroke: an updated pooled analysis of ECASS, ATLANTIS, NINDS, and EPITHET trials. Lancet (London, England). 2010; 375(9727):1695-703. [pubmed]
Thomalla G, Simonsen CZ, Boutitie F, et al. MRI-Guided Thrombolysis for Stroke with Unknown Time of Onset. The New England journal of medicine. 2018; 379(7):611-622. PMID: 29766770 ( The WAKE UP trial)
Morgenstern, J. Stroke thrombolytics update 1: The WAKE UP trial, First10EM, January 27, 2020. Available at:
https://doi.org/10.51684/FIRS.10779
This post provoked a very lengthy discussion on twitter. Andrew Althouse (@ADAlthousePhD) wrote quite the lengthy dissertation about stopping trials early, and where I might have got things wrong. It is probably too long to reproduce in it’s entirety, but for those who are interested, the entire twitter feed is very interesting.
I will briefly summarize my understanding of his main points and add my comments:
First: when I talk about the law of large numbers, I make the assumption that if there is going to be regression to the mean, it is going to be towards the null hypothesis. Mathematically, this isn’t true. Small trials are likely to have bigger deviations, but those deviations should be equally likely on both sides of the true number. Therefore, you could actually “regresses to the mean” but trend towards a larger difference between the two groups (because that is the true number).
Mathematically, that objection is entirely correct, but I don’t think it holds in medicine. In medicine, the vast majority of our trials are negative, and therefore it is more likely that the true number is consistent with the null hypothesis. I think regression to the mean, in medicine, is more likely to make benefits disappear. In fact, this has been studied in medicine. Bassler and colleagues (2010) looked at 91 RCTs that were stopped early, and compared them to 424 matched RCTs of the same topics that were not stopped early. The effect sizes were smaller when the trials were completed. Of trials stopped early for benefit, that benefit was not seen in 60% of the matched trials that were completed. Again, I think it is important to remember that trials are not stopped randomly.
To emphasize this: regression to the mean does not mean the results will regress back towards no difference. The results will regress back towards the true number. However, because most medical trials are negative, the true number is also more likely to be no difference.
Second: The concern that the mortality benefit seen here could become statistically significant is logically inconsistent with my initial concern about regression to the mean.
I agree that these two sources of bias from stopping trials early appear to push the results in different directions. I tried to make that clear in the initial write up. However, that doesn’t make it wrong. Stopping trials early reduces their power. We already have a problem in medical research that we power trials for benefit, but not for the less common (but potentially more important) harms.
It is true that the mortality number could have also regressed towards the mean, so why do I say that it is likely that this result would have become statistically significant had the trial been completed? For the exact same reason we just discussed: the numbers should regress to the true number, and increased mortality is a consistent feature of these tPa trials. (See all 3 trials discussed in the EXTEND post.) I expect that the absolute difference seen here is close to the true number, so adding more events and shrinking the confidence intervals is highly likely to make it statistically significant.
Third: Stopping trials early for futility is necessary, because it is unethical to enroll patients in trials if we know the primary objective of the trial will not benefit from additional patients.
This is a tricky one. I think people are missing a huge part of the ethical equation. Once a trial has been declared futile, we know that we won’t see a benefit. However, there are multiple other outcomes in the trial that might be very important. Stopping these trials early often means that we are left with more uncertainty, and that uncertainty leads to more trials. Consequently, instead of enrolling a small number of patients in the trial already have, we enroll a much larger number of patients in subsequent trials (or worse, we just use the treatment clinically). If adding the few extra patients to the initial trial was going to be enough to prove that the treatment was not just futile, but also harmful, many patients could be saved from being exposed. Those patients never seem to be considered in our ethical conversation, and I think the must be.
Fourth: my general comments about research degrees of freedom and p-hacking make it sound like I am accusing the researchers of academic fraud or dishonesty. (It sounds like I am implying that they were peaking at their data and deciding when to stop).
This is a good criticism. I did not intend for my words to read that way. Although we know that this type of behavior does occur, Andrew rightly points out that it is very difficult to do in a highly regulated clinical trial. I was attempting to educate about the general concept, and it came across too specific. If I find time, I will try to rephrase that section.
However, we both agree that this trial was stopped early for a bizzare reason. Probably the right response is to feel sorry for the researchers. They did a ton of work, only to lose their funding. That is as unfortunate for them as it is for us.
Finally: Andrew thinks I come across as a pessimist, rather than a skeptic. In other words, from what he has read on the blog, he gets the impression that I would never suggest a treatment, no matter what, because trials are always imperfect. He worries that such pessimism could spread, and readers of my blog could come away with the sense that all science is flawed, and no studies should be trusted. (Considering that I am a huge advocate of science based medicine, if this is the impression I am creating, I am failing miserably.)
I don’t think that is true, although I am much more likely to write about bad research than good. We have a long history in medicine of jumping on treatment bandwagons too early. We rush to the newest treatments, but see reversals and harms to our patients time and again. One of the primary objectives of this blog is to point out the harm we do through over-treatment and over-testing, often as a result of overzealous adaptation of incomplete or imperfect evidence. So yes, many of my posts have a negative tone.
However, I know I have changed my practice countless times over the last decade in response to new evidence, and I hope I have been able to share those practice changes with you. I recommend many practices, while simultaneously recognizing the limitations of the evidence. (See, for example, the use of femoral nerve blocks in hip fractures, the use of vasopressors through peripheral IVs, or the use of topical anesthetics for corneal abrasions.) I try to look for positive practice changes in seemingly negative trials. (See anti-emetics or ED-ICUs.) I have even delved into the incredibly weak psychology literature, to discuss practices that I think can help ED docs deal with stress. The goal of this blog is not to tell you what a single study says, or how to practice. The goal is to teach critical appraisal skills, emphasize that evidence based medicine is easy, and get everyone thinking for themselves. That is my goal. Only my readers will be able to tell me if I am successful.


5 thoughts on “Stroke thrombolytics update 1: The WAKE UP trial”
Hey Justin,
thank you for your post! I am looking forward to tomorrow. I can follow all of your points except for this one here:
“Although we could certainly make MRI and neuroradiologists more available, the tiny number of eligible patients might make that a poor investment of resources. They only managed to include 1.6 patients a year at each stroke center.”
I would think that – provided that this screening method had proven guideline-changing-efficient – you could treat a lot more patients this way than the 1.6/center/year. They were only allowed to look at patients who had a wake-up-stroke or presented outside of the 4.5h windows some other way, right? So the large number of patients that are right now treated according to the guidelines is not included in this group. Not sure about the exact figures though, maybe I am exaggerating here, but I feel like there were about 1-4 patients per week treated with alteplase during my neurology rotation at an 800-bed-clinic.
Agree, if people are willing to use this technique on people who are currently being treated. 1) I don’t see that happening, as too many people believe thrombolytics are proven under 4.5 hours. 2) This MRI technique wouldn’t help much, aside from eliminating some mimics, because it is just confirming the 4.5 hour cut-off. If a person can talk, their story is probably more accurate than the MRI. 3) We have to consider the harms. These studies take time. Is it worth the delay to treatment? We would need to see it studied in the 4.5 hour window to be sure.
But I agree – if we could find a true “STEMI equivalent” it would be more widely applicable. That comment was about this specific attempt to extend treatment to more patients using MRI.
All that matters is that Genentech makes money.
Everything else is irrelevant.