
Dr Anand Senthi (@drsenthi) posted a great talk about what he calls “EBM 2.0” entitled “Evidence Based Fraud & the End of Statistical Significance”. I think readers of this blog will find the talk really interesting, and potentially enlightening.
The Talk
I strongly recommend watching the talk in its entirety. Whether you are an EBM aficionado, or just a doctor looking to do the best things for your patients, there is a lot to learn from this talk. Below, I will highlight what I think are some of the key lessons (plus maybe a point or two of disagreement).
You can find a lot more from Dr. Senthi on his website.
The overall message: Most published research findings are false
This idea comes straight from the famous paper by John Ioannidis, “Why Most Published Research Findings Are False”. (Ioannidis 2005) I love this paper. Through Jerry Hoffman, this paper helped develop my medical skepticism. It won’t be a surprise to anyone who reads this blog that the conclusions of many medical papers are wrong.
There are a number of reasons that research findings could be false. A massive problem in medicine is that we allow our science to be performed by people who have a vested interest in the outcomes. We let drug companies study their own drugs and device manufacturers study their own devices. Allowing that conflict of interest is insane, and completely corrupts the science available in medicine. As big of a problem as it is, conflict of interest isn’t the main reason that Dr. Senthi argues that most medical findings are false.
Dr Senthi’s primary concerns are issues that will be very familiar to readers of this blog: bias, poor methodology, and misunderstandings about statistics. According to the Ioannidis paper, research findings are more likely to be false when the number of studies is small, when the effect size is small, when research looks at a large number of outcomes (especially without preselecting those outcomes), when there is flexibility in the design or reporting of a study, when there are financial or other conflicts of interest, and when we prioritize “statistical significance”. (Ioannidis 2005) The lack of biologic plausibility is another important source of misleading research findings. There are all incredibly important issues.
However, I don’t actually think that most published research findings are false. Outside of outright fraud (which unfortunately does happen in medical science), research findings aren’t “false”. Bias can make results misleading. The results of a trial may represent chance rather than a true finding. The findings can be misinterpreted (and they commonly are in medicine), but they cannot be false.
That distinction may seem finicky, but I think it is important. I agree with Drs. Ioannidis and Senthi about all the issues that we face when interpreting data, but I dislike calling the findings false. Some trials are so biased that the findings are practically unusable. They represent the trial’s methodology rather than some underlying truth in the world. However, in general, I think the issue lies in the interpretation of the findings, rather than with the findings themselves. (The findings of NINDS are not false, but they have certainly been widely misinterpreted in medicine.)
False findings and medical reversals
The existence of “medical reversals” seems to contradict my position. As Dr. Senthi argues, medical reversals seem to be an indication that the original research findings were false. In making this argument, he brings up another classic study, “A Decade of Reversal” by Vinay Prasad and colleagues. (Prasad 2013) In this paper, they looked at every study in the New England Journal of Medicine over a decade. Of 363 articles looking at “standard care”, 146 (40%) reversed current practice. Other studies come to the same conclusions: when we bother to test it, what we consider “standard care” fails regularly. (Herrera-Perez 2019.)
That sounds pretty damning, and I believe the results. Current practice is constantly being contradicted by new trials. And these reversal only represent the tip of the iceberg, because a practice can only be reversed if it is studied. Most of the time, we don’t bother to study current practice. We declare medical practices “standard care” based on crappy research and never bother to check the results. (Even if someone wanted to check the results, it is often impossible, as people argue that it is unethical to randomize away from “standard care”.)
However, I don’t think that means that the prior research findings were “false”. Medicine has a bad habit of getting carried away by the results of a single trial. We see a potential benefit, ignore the weaknesses of the research, and excitedly declare things “standard of care”. That is a huge mistake that has consistently harmed our patients. However, it doesn’t mean that the research was false; it means that our conclusions were false.
Would anyone be surprised if an RCT of tPA for stroke showed no benefit? Of course not. We know that the science says tPa probably doesn’t work, despite being widely considered the standard of care. Usually, studies that are considered “reversals” in the wider world of medicine simply demonstrate what EBM proponents have been saying all along. These “reversals” are usually perfectly consistent with the existing evidence.
The need for replication
Even when new studies truly conflict with prior high quality research, I don’t see them as “reversals” or the prior finding as “false”. Replication is a core tenet of science. One study is never enough. The results of a single study could easily be from chance alone. The single study could be biased, even if that bias isn’t obvious in the methods section. Science is not shaped by single studies, but by the accumulation of evidence. Conflicting studies are not “reversals”. They are extra data points that drive us closer to the ever-elusive truth.
Bias and Chance
There are two major sources of error in research: chance and bias.
Bias is any factor that systematically pushes the results of a trial away from the truth. There are many biases. They can arise in the design of a trial, its analysis, and even in the presentation of data. Most bias is unintentional (although conflict of interest also generates the spectre of intentional bias). Bias, at least to some extent, is unavoidable.
Even if a trial managed to be perfectly fair (free from bias), the results could still be wrong by chance alone. Chance is why we use statistics in research. If I flip a fair coin 100 times, it is unlikely that I will end up with exactly 50 heads. If that is the case, how can I be sure that the coin is truly fair?
Unfortunately, the combination of chance and bias can be incredibly misleading, even to the trained eye. These two factors are the source of the many “reversals” that we see in medicine.
I have spent a lot of time writing about bias on this blog, both in the glossary of biases and in the many individual critical appraisals. I have purposefully spent far more time writing about bias than chance. To EBM novices, that often seems counter-intuitive. Statistics seem like the “sciency” part – they seem like the core of evidence based medicine – but I think bias is far more important. There is no value in measuring the results of a race down to the thousandth of a second, if one runner had a huge head-start or cheated, so that the race was unfair from the outset. Similarly, there is no point in even discussing a p value if the trial results are too biased.
P value problems #1: Our standards are way too low
Let’s talk a little bit about statistics. (I wrote an entire post about the p value at one point, but it seems like that post was never published.) In medicine, a p value of 0.05 is treated like it is somehow magic; as if it were a divine threshold that perfectly sorts truth from fiction. It is not. It is an arbitrary threshold, and a very low one at that.
In other realms of science, a p value of 0.05 is a laughably low bar. The standard in physics is 5 sigma, or a p value of 0.0000003. (Fatovich 2017) This is a standard that is more than 100,000 times less likely to occur by chance alone. It is what we required to confirm the existence of the Higgs boson. In that context, the p value of 0.05 doesn’t seem so special, does it?
There are potential reasons to use a lower threshold (higher p value) in medicine, considering that our experimental subjects are people. However, there is also a significant harm in using a lower threshold, in that false positives occur far more often, and those false positives may ultimately harm many more people. (Physicists may disagree, but I think it is more important to be sure about the efficacy and safety of thrombolytics in stroke than it is to be sure about the existence of the Higgs boson.)
P value problems #2: The p value assumes no bias
In order to calculate a p value, we assume the “null hypothesis”. A p value tells us how likely our collected data is, assuming the null hypothesis is true. A low p value indicates that our assumptions are unlikely to be true. Because the only explicit assumption was the null hypothesis, we use the low p value to reject the null hypothesis.
However, the p value actually makes another really important assumption that is rarely discussed: it assumes that the trial has no bias. Clearly, that is a very poor assumption. A p value less than 0.05 actually means that either the null hypothesis was wrong or that the study was biased (or a combination of both). It actually tests both assumptions simultaneously. However, we tend to forget about that second part, even though it is probably the more likely explanation.
(Yes, I know, some of this stuff sounds complicated. Trust me, EBM is easy.)
P value problems #3: The p value doesn’t define reality
The p value is incredibly easy to misunderstand. It is a statistical measure of a null hypothesis. A low p value tells us that, according to this data set, the null hypothesis is unlikely to be true, but the null hypothesis is just something that we made up. The p value doesn’t give us any information about what alternative hypothesis is likely to be true.
Consider a game played between the Michael Jordan era Chicago Bulls and a randomly selected high school team. We expect the Bulls to be the better team, so we set our null hypothesis as “there is no difference between these two teams”. The high school team wins 100-80, and our statistician tells us that there was less than a 5% chance of that result occuring, assuming the teams were the same. The null hypothesis has been rejected, but what does that mean? Should we assume that the high school team is better than the Bulls? That seems like the opposite of the null hypothesis, and is the conclusion we frequently make in medicine, but it isn’t the only explanation. Maybe the game was unfair. Maybe there was a crooked referee betting on the game. Maybe the Bulls let the kids win. We can reject the null hypothesis – the idea that there is no difference between the two teams – but that doesn’t help us determine what the difference really is.
The p value allows us to reject the null hypothesis, but it is not a measure of reality. Too often in medicine, we use the p value as a hard threshold. If a p value is lower than 0.05, we declare that the trial is positive, and assume the treatment must work. If the p value is higher than 0.05, we declare the trial negative. (Of course, it is silly to treat the difference between p=0.049 and p=0.051 as somehow game changing.) We decide “standard of care” based on the p value, but the p value doesn’t define truth. In the eyes of the statistician who invented the p value – Ronald Fisher – it is just an informal way to judge whether data was worthy of a second look. We need to stop acting like the p value defines reality.
Here are some statements about the p value from the American Statistical Association: (Wasserstein 2016)
- “P-values do not measure the probability that the studied hypothesis is true, or the probability that the data were produced by random chance alone.”
- “Scientific conclusions and business or policy decisions should not be based only on whether a p-value passes a specific threshold.”
- “By itself, a p-value does not provide a good measure of evidence regarding a model or hypothesis.”
The P value and Bayesian analysis
The love affair with p = 0.05 in medicine has created a culture that completely ignores pretest probability. Imagine two different trials, both with a p value less than 0.05. The conclusion of trial #1 is the sun is likely to rise again tomorrow morning. The conclusion of trial #2 is that the Loch Ness monster exists. Both trials use similar methodology and both have the exact same p value. Do you trust the results equally?
Of course not. Scientific studies don’t exist in a vacuum. Each new study builds on what we already know, and must be interpreted within the context of existing science. Unfortunately, we have completely lost touch with this core principle in medicine. We routinely accept or reject trials based on their p values alone.
A classic example of this would be the stroke literature. When the NINDS-2 trial was published, we completely changed the way we manage stroke based on a “positive trial” (with a borderline p value of 0.02). Ignoring the many sources of bias in NINDS, there is no way that a p value of 0.02 should have convinced us that thrombolytics were the standard of care. Three negative trials had already been published. Even in NINDS, thrombolytics had no effect at 24 hours. Our pretest probability that they would have an effect at 3 months should have been very low. It should have been clear that the results were more likely to represent bias or chance than the truth. But the p value reigns supreme in medicine and the context was ignored.
In the next 5 years, there were 5 more trials published, 4 of which were stopped early because of clear harms to the patients, and 1 that showed no difference, but we were still convinced by the p value of 0.02 in NINDS-2. Then the ECASS-III trial was published, and once again the medical world rapidly changed because of a single p value, completely ignoring the multiple published studies demonstrating harm.
Disasters like this illustrate the incredible harms of interpreting p values in isolation. Trials are not black and white; positive or negative. They need to be interpreted in the context of the existing science. You need to know the pretest probability.
This can be done informally. For example, I can easily reject any positive trial of homeopathy, because I know the pretest probability of it working is 0. However, there is a more formal approach to incorporating pretest probability called Bayes’ theorem. In this approach, you decide on your pretest probability (based on prior science) and then use the p value like a likelihood ratio to determine your post-test probability based on the results of the new study. (Nuzzo 2014) (I have previously discussed how important pretest probability is when interpreting clinical tests. The same is true when we are interpreting research.)
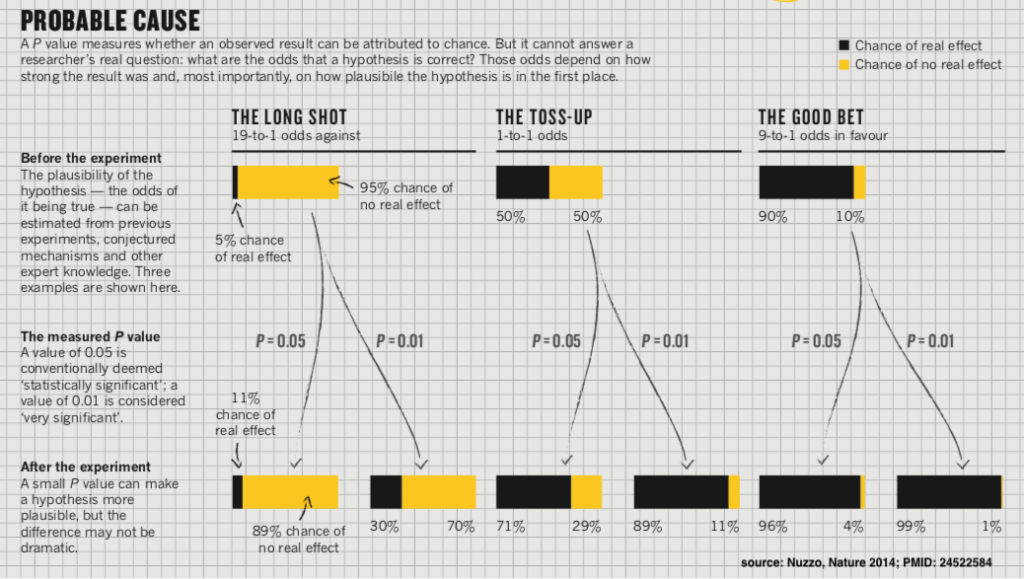
This approach quickly illustrates our common misconceptions about the p value. A p value of 0.01 is often interpreted in medicine as indicating that there is a 99% chance the results of the trial are true. Even if we ignore the role of bias and just focus on chance, this interpretation is incorrect. If a medical treatment has a 50% chance of working before we run a trial, and we see a p value of 0.01, the post-test probability is 89%. That is pretty good, but it still leaves an 11% chance that the treatment doesn’t work (which can be very significant, considering the harms of our treatments.)
Unfortunately, a 50% pretest probability is almost unheard of in medicine. Most novel therapies don’t work. Of all the new drugs we bring to phase 1 trials, only a small fraction end up helping patients. If we start with the more realistic pretest probability of 5%, and have a “positive” trial with a p-value of 0.049, the post-test probability of that trial reflecting reality is only 11%. Now, despite a positive trial, there is still a 90% chance the treatment doesn’t work! (And this doesn’t even account for the role of bias.)
Returning to the Chicago Bulls example, we knew before the game was played that the Bulls were better than any highschool team they could play. Our pretest probability of the highschool team being better should have been incredibly low. Therefore, even if your statistician told us that the p value for this single game was less than 0.000001, we would still believe that the Bulls are probably better after the game was played.
The sports analogy also provides a good lesson in replication. There is a reason many sport use a best of seven format in the playoffs. We know that anything can happen in a single game. A single game doesn’t necessarily define which is the better team, but as you play more games, it becomes more likely the the team that wins more games is truly the better team.
For a little more detail on how to use p values in a Bayesian analysis, see Dr. Senthi’s website.
Stop saying “statistically significant”
On its own, a p value tells us almost nothing. We need to understand the trial’s context. We need to know the pretest probability. We need to consider bias. Therefore, saying that a trial is “statistically significant” is pretty meaningless. Some people, including prominent statisticians and Dr. Senthi, are arguing that we should never say “statistically significant”. (Wasserstein 2019)
I think they are probably right. The phrase is just too misunderstood to be useful. I will admit that I still frequently refer to statistical significance. It feels like a useful shorthand. However, communication is about the audience, and there is a very good chance that the audience doesn’t understand these words in the way that I intend them. Although it might be hard to break the habit, this seems like a good recommendation.
What do we do instead?
After imploring us to stop saying “statistically significant”, Wasserstein provides a really good recommendation: “Accept uncertainty. Be thoughtful, open, and modest.” (Wasserstein 2019)
We have been trying to use the p value to transform messy data into something black and white. That just isn’t possible. We have to accept some degree of uncertainty in science, and realize that certainty is built on the cumulation of evidence, not from a single study. (Wasserstein 2019)
We need to be thoughtful about prior evidence, prior plausibility, meaningful effect sizes, our available statistical tools, and how we communicate certainty. (Wasserstein 2019) Rather than just presenting a p value, it might be a very good idea for researchers to present an estimate of how likely it is that their results are true. This would involve clearly stating a pretest probability, and discussing their results within that context. Even better would be discussing the results across a variety of pretest probabilities. Of course, we also need to be thoughtful about trial design, and the many sources of bias that can lead us astray.
Research needs to be open. We need to register our research in advance (and stick with our planned methodology). We need to be open about every statistical analysis that was performed. Every result needs to be published. Every trial needs to be published. We need to be open to having others check and duplicate our work (which is the backbone of science). (Wasserstein 2019)
And we need to be modest. Academic structures unfortunately don’t reward modesty, but science is a humbling pursuit. We engage in science precisely because we might be wrong. (There is no point in running a trial if you already know the answer.) We need to be modest in our conclusions from individual trials. We need to be modest in encouraging others to prove us wrong and identify our errors. (Wasserstein 2019)
What is EBM 2.0?
You can read about EBM 2.0 here. My summary of the key principles would be:
- We can’t even begin to have meaningful conversations about science until we all understand the above limitations. The vast majority of doctors don’t understand these core EBM principles. They treat p values as black and white. They will declare a practice standard of care after a single study. You can’t possibly discuss the shortcomings of the stroke literature with someone who doesn’t understand research bias, and treats a p value of 0.02 as gold. The first task of EBM 2.0 is education. We must share these concepts as widely as possible.
- Assume bias in every study. There is no study that exists without bias. The results of all studies need to be interpreted with the understanding that bias could be, and likely is, shaping the results.
- We need to understand the role of chance in trials. We should stop using the phrase “statistically significant” and instead focus on using the reported p values to transform pretest probabilities into estimated post test probabilities.
- We have to remember that statistical measures assume no bias, which is almost always a bad assumption. Before even considering the statistics of a trial, we must examine the methodology, and consider the impacts of bias.
- We need to use these principles to reassess our previous decisions. Too many medical practices that are considered “standards of care” are based on misunderstandings about science. We need to go back and systematically reassess these practices.
- We need to fix the way that medical studies are published. Studies must be pre-registered in order to be published and all registered trials must be published. Similarly, every measured outcome must be pre-registered and every registered outcome must be published.
I don’t like “EBM 2.0”
I agree with everything that Dr. Senthi has to say, but I really dislike the idea of “EBM 2.0”. Labelling it EBM 2.0 seems to indicate that there is something wrong with EBM, but the EBM 2.0 described by Dr. Senthi is no different than EBM as I know it. Identifying and understanding bias is central to evidence based medicine, as is understanding the limitations of statistical tests. EBM practitioners have always worked hard to place individual studies within their broader scientific context.
Everything said is correct, but everything said just describes properly practiced evidence based medicine.
But it might be necessary
As much as I dislike rebranding good EBM practice as something shiny and new, Dr. Senthi has a point. Many people have spent a very long time talking about these issues. I believe Jerry Hoffman was actually teaching these concepts before I was born. However, the same misconceptions persist. Decade after decade, we see the same errors made. It isn’t clear that we are making progress.
Perhaps we need a rebrand to draw attention to these issues.
We definitely need better science teaching in medical schools. Way less time should be spent on memorizing useless things like the Krebs cycle, and way more time on scientific bias and critical thinking. We need to remove the financial conflict of interest from medical science. We need to fix the corrupt publications systems. I don’t know whether it is necessary to rebrand good scientific practice as “EBM 2.0”, but if it helps us accomplish these goals, you can count me in.
Evidence Based Medicine Resources
You can find Dr. Senthi’s EBM 2.0 resources at EBM2point0.com
You can find a general approach to clinical appraisal in the post “EBM is Easy”.
The Glossary of Scientific Bias
References
Fatovich DM, Phillips M. The probability of probability and research truths. Emerg Med Australas. 2017;29(2):242‐244. doi:10.1111/1742-6723.12740 PMID: 28201852
Herrera-Perez D, Haslam A, Crain T, et al. A comprehensive review of randomized clinical trials in three medical journals reveals 396 medical reversals. Elife. 2019;8:e45183. Published 2019 Jun 11. doi:10.7554/eLife.45183 PMID: 31182188
Ioannidis JP. Why most published research findings are false. PLoS Med. 2005;2(8):e124. doi:10.1371/journal.pmed.0020124 PMID: 16060722
Nuzzo R. Scientific method: statistical errors. Nature. 2014;506(7487):150‐152. doi:10.1038/506150a PMID: 24522584
Prasad V, Vandross A, Toomey C, et al. A decade of reversal: an analysis of 146 contradicted medical practices. Mayo Clin Proc. 2013;88(8):790‐798. doi:10.1016/j.mayocp.2013.05.012 PMID: 23871230
Wasserstein RL, Lazar NA. The ASA Statement on -Values: Context, Process, and Purpose The American Statistician. 2016; 70(2):129-133. DOI: 10.1080/00031305.2016.1154108
Wasserstein RL, Schirm AL, Lazar NA. Moving to a World Beyond “ < 0.05” The American Statistician. 2019; 73(sup1):1-19. DOI: 10.1080/00031305.2019.1583913
Morgenstern, J. EBM 2.0, First10EM, May 25, 2020. Available at:
https://doi.org/10.51684/FIRS.23648




2 thoughts on “EBM 2.0”
Amen and hallelujah!!
To this amazing post I’d just add the communication aspect . My own conclusion on all this (from Jerome Hoffman, to Ioanidis to Bernard Lown, John Mandrola and Prasad ) is that Rick Body (om suffering) is right . Much of what we think work , doesn’t – in fact often it harms, as we all know.
Respect , Communication and efforts to reduce suffering (being a good communicator – both diagnostic and therapy-wise , doing shared decision making , trying to be empathetic and actively listening etc) probably does much more for the individual patient than 90% of the medication we have .
EBM is the way forward (no matter the name) to perpahps someday free our societies from the mess that we currently are in (not just covid19)- and good communication should be a core element .
“More is better, or less is better are improper catch phrases. The ultimate litmus is what is best for the uniquely individual patient” Bernard Lowns blog – Social Responsibility of Physicians (Essay 29)
As always , thanks Justin for your hard and excellent work!
All the best
Peter
I remember an EBM Activity from Med School. We had to pick a patient. Formulate a clinical question on that patient. Find a paper to answer that clinical question. Write a report answering a series of EBM questions on that paper. I remember doing it in my psych rotation and choosing to compare benzos and haldol for acute sedation. I have no recollection of the questions, but I remember getting it done in an afternoon.
I know that bias and chance were discussed, along with concepts like pre-test probability, and likelihood ratios and of course that magic p-value, but it all floated away, untethered to real world practice. And now, I have an appreciation for what the words mean, but no idea of how to apply them in a meaningful way that affect my practice. I recognize that I rely way too much on blogs and other docs to package my information for me.
I feel like we need a total rethink of how we teach EBM to ensure that every generation of docs gets better at it. Not teaching statistics, but interpretation of results. And like all teaching, it needs iterative practice to ensure that docs get it and use it. Perhaps even courses a la ACLS on EBM and interpreting results.